
UOMOP
성능 향상 using (# of filters, depth) 본문
1. 각종 모듈 호출
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Activation, MaxPooling2D,\
Flatten, Dropout, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping2. 각종 함수 정의
def make_zero_to_one(images, labels) :
images = np.array(images/255., dtype = np.float32)
labels = np.array(labels, dtype = np.float32)
return images, labels
def ohe(labels) :
labels = to_categorical(labels)
return labels
def tr_val_test(train_images, train_labels, test_images, test_labels, val_rate) :
tr_images, val_images, tr_labels, val_labels = \
train_test_split(train_images, train_labels, test_size = val_rate)
return (tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels)
def create_before_model(tr_images, verbose):
input_size = tr_images.shape[1]
input_tensor = Input(shape=(input_size, input_size, 3))
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same')(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=64, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=64, kernel_size=3, padding='same')(x)
x = Activation('relu')(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=2)(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Flatten(name='flatten')(x)
x = Dropout(rate=0.5)(x)
x = Dense(300, activation='relu', name='fc1')(x)
x = Dropout(rate=0.3)(x)
output = Dense(10, activation='softmax', name='output')(x)
model = Model(inputs=input_tensor, outputs=output)
return model
if verbose == True :
model.summary()
def create_after_model(tr_images, verbose):
input_size = tr_images.shape[1]
input_tensor = Input(shape=(input_size, input_size, 3))
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same')(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = Activation('relu')(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=2)(x)
x = Conv2D(filters=256, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=256, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=512, kernel_size=3, strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Flatten(name='flatten')(x)
x = Dropout(rate=0.5)(x)
x = Dense(300, activation='relu', name='fc1')(x)
x = Dropout(rate=0.3)(x)
output = Dense(10, activation='softmax', name='output')(x)
model = Model(inputs=input_tensor, outputs=output)
return model
if verbose == True :
model.summary
def lets_compare_two(before, after) :
fig, axs = plt.subplots(nrows = 1, ncols = 2, figsize = (22, 6))
axs[0].plot(before.history["val_accuracy"], label = "before")
axs[0].plot(after.history["val_accuracy"], label = "after")
axs[0].set_title("val_accuracy")
axs[0].set_xlabel("epochs")
axs[0].set_ylabel("val_acc")
axs[0].legend()
axs[1].plot(before.history["val_loss"], label = "before")
axs[1].plot(after.history["val_loss"], label = "after")
axs[1].set_title("val_loss")
axs[1].set_xlabel("epochs")
axs[1].set_ylabel("val_loss")
axs[1].legend()
plt.show()3. 데이터 불러오기 및 전처리 과정
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_images, train_labels = make_zero_to_one(train_images, train_labels)
test_images, test_labels = make_zero_to_one(test_images, test_labels)
train_labels = ohe(train_labels)
test_labels = ohe(test_labels)
(tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels) = \
tr_val_test(train_images, train_labels, test_images, test_labels, val_rate = 0.15)4. 모델 생성(기존)및 편집
model_before = create_before_model(tr_images, verbose = True)
model_before.compile(optimizer = Adam(learning_rate = 0.001), loss = "categorical_crossentropy", metrics = ["accuracy"])
rlr = ReduceLROnPlateau(monitor = "val_loss", factor = 0.2, patience = 5, mode = "min", verbose = True)
ely = EarlyStopping(monitor = "val_loss", patience = 13, mode = "min", verbose = True)
result_before = model_before.fit(x = tr_images, y = tr_labels, batch_size = 32, epochs = 40, shuffle = True,
validation_data = (val_images, val_labels), callbacks = [rlr, ely])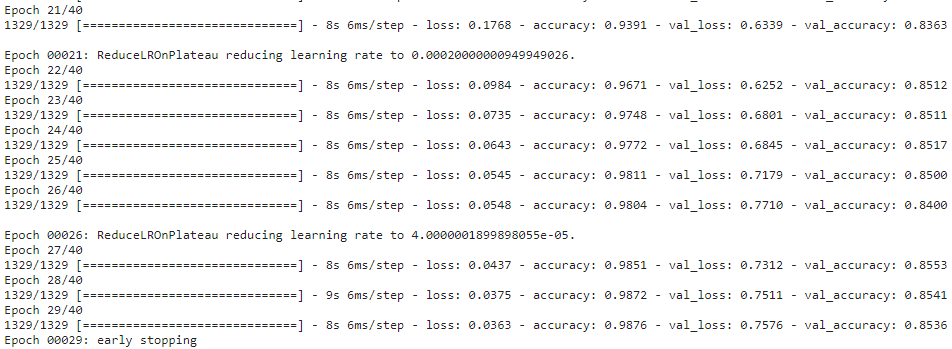
5. 모델 생성(수정)및 편집
model_after = create_after_model(tr_images, verbose = True)
model_after.compile(optimizer = Adam(learning_rate = 0.001), loss = "categorical_crossentropy", metrics = ["accuracy"])
rlr = ReduceLROnPlateau(monitor = "val_loss", factor = 0.2, patience = 5, mode = "min", verbose = True)
ely = EarlyStopping(monitor = "val_loss", patience = 13, mode = "min", verbose = True)
result_after = model_after.fit(x = tr_images, y = tr_labels, batch_size = 32, epochs = 40, shuffle = True,
validation_data = (val_images, val_labels), callbacks = [rlr, ely])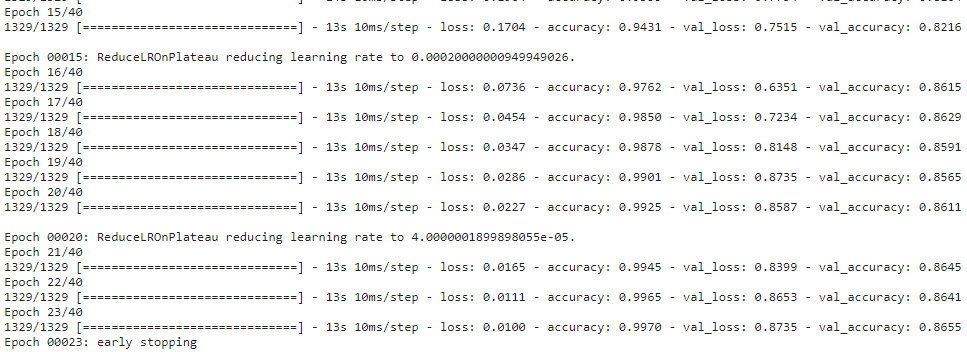
6. 성능 비교
lets_compare_two(result_before, result_after)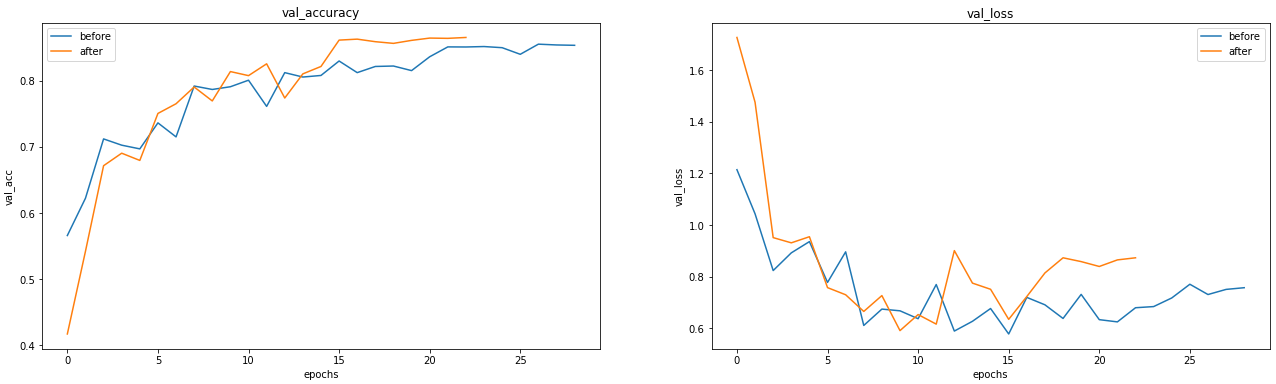
모델의 깊이와 filter의 개수를 늘리면서 성능이 개선되는 것을 확인해보려고 하였으나, 눈에 띄게 달라지는 점은 찾을 수 없었다.

'Ai > DL' 카테고리의 다른 글
| Overfitting 극복 using 가중치 규제 (0) | 2022.02.10 |
|---|---|
| Overfitting 극복 using GAP(GlobalAveragePooling) (0) | 2022.02.09 |
| 성능 향상 using callback (0) | 2022.02.09 |
| 성능 향상 using batch size (0) | 2022.02.09 |
| 성능 향상 using shuffle (0) | 2022.02.09 |
'Ai/DL' Related Articles
more




Comments