
UOMOP
성능 향상 using callback 본문
1. 각종 모듈 호출
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Activation, MaxPooling2D,\
Flatten, Dropout, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping2. 각종 함수 정의
def make_zero_to_one(images, labels) :
images = np.array(images/255., dtype = np.float32)
labels = np.array(labels, dtype = np.float32)
return images, labels
def ohe(labels) :
labels = to_categorical(labels)
return labels
def tr_val_test(train_images, train_labels, test_images, test_labels, val_rate) :
tr_images, val_images, tr_labels, val_labels = \
train_test_split(train_images, train_labels, test_size = val_rate)
return (tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels)
def create_model(images, verbose) :
input_size = (images.shape)[1]
input_tensor = Input(shape = (input_size, input_size, 3))
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same')(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=64, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=64, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=2)(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=2)(x)
# cifar10의 클래스가 10개 이므로 마지막 classification의 Dense layer units갯수는 10
x = Flatten(name='flatten')(x)
x = Dropout(rate=0.5)(x)
x = Dense(300, activation='relu', name='fc1')(x)
x = Dropout(rate=0.3)(x)
output = Dense(10, activation='softmax', name='output')(x)
model = Model(inputs=input_tensor, outputs=output)
if verbose:
model.summary()
return model3. 데이터 호출 및 전처리
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_images, train_labels = make_zero_to_one(train_images, train_labels)
test_images, test_labels = make_zero_to_one(test_images, test_labels)
train_labels = ohe(train_labels)
test_labels = ohe(test_labels)
(tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels) = \
tr_val_test(train_images, train_labels, test_images, test_labels, val_rate = 0.15)4. 기존 저장된 모델 삭제
!rm *.hdf5
5. 모델 생성 및 학습
model = create_model(tr_images, verbose=True)
model.compile(optimizer = Adam(lr = 0.001), loss = "categorical_crossentropy", metrics = ["accuracy"])
mcp = ModelCheckpoint(filepath = "/kaggle/working/weights.{epoch:02d}-{val_loss:.2f}.hdf5",
monitor = "val_loss",
save_best_only = True,
save_weights_only = True,
mode = "min",
period = 1,
verbose = False)
rlr = ReduceLROnPlateau(monitors = "val_loss", factor = 0.2, patience = 5, mode = "min", verbose = True)
ely = EarlyStopping(monitor = "val_loss", patience = 10, mode = "min", verbose = True)
result = model.fit(tr_images, tr_labels, batch_size = 32, epochs = 30, shuffle = True, \
validation_data = (val_images, val_labels), callbacks = [mcp, rlr, ely])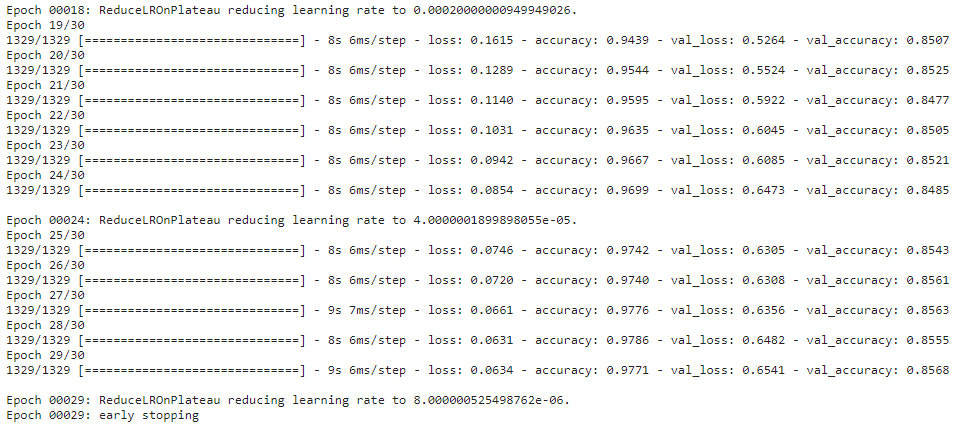
6. 마지막까지 학습된 모델로 성능 평가
model.evaluate(test_images, test_labels, batch_size = 32)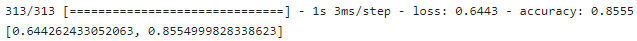
7. 저장된 weight 확인해보기
!ls -lia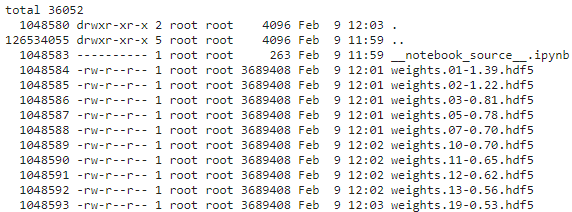
8. 최적 weight를 모델로 재로딩한 후, 테스트 데이터로 다시 평가하기
model = create_model(tr_images, verbose = True)
model.compile(optimizer = Adam(learning_rate = 0.001), loss = "categorical_crossentropy", \
metrics = ["accuracy"])
model.load_weights("/kaggle/working/weights.19-0.53.hdf5")
model.evaluate(test_images, test_labels, batch_size = 32)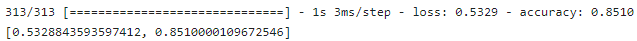

'Ai > DL' 카테고리의 다른 글
| Overfitting 극복 using GAP(GlobalAveragePooling) (0) | 2022.02.09 |
|---|---|
| 성능 향상 using (# of filters, depth) (0) | 2022.02.09 |
| 성능 향상 using batch size (0) | 2022.02.09 |
| 성능 향상 using shuffle (0) | 2022.02.09 |
| 성능 향상 using Batch_normalization (0) | 2022.02.07 |
'Ai/DL' Related Articles
more




Comments