
UOMOP
성능 향상 using batch size 본문
1. 각종 모듈 호출
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.layers import Input, Conv2D, Activation, MaxPooling2D, Flatten, Dense, Dropout,\
BatchNormalization
from tensorflow.keras.optimizers import Adam, RMSprop2. 각종 함수 정의
def make_zero_to_one(images, labels) :
images = np.array(images/255., dtype = np.float32)
labels = np.array(labels, dtype = np.float32)
return images, labels
def ohe(labels) :
labels = to_categorical(labels)
return labels
def sper_tr_val(train_images, train_labels, test_images, test_labels, validation_rate) :
tr_images, val_images, tr_labels, val_labels = \
train_test_split(train_images, train_labels, test_size = validation_rate)
return (tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels)
def create_model():
input_size = (train_images.shape[1])
input_tensor = Input(shape = (input_size, input_size, 3))
x = Conv2D(filters = 32, kernel_size = (3, 3), padding = "same")(input_tensor)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(filters = 32, kernel_size = (3, 3), padding = "same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = MaxPooling2D(pool_size = (2, 2))(x)
x = Conv2D(filters = 64, kernel_size = (3, 3), padding = "same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(filters = 64, kernel_size = (3, 3), padding = "same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = MaxPooling2D(pool_size = (2, 2))(x)
x = Conv2D(filters = 128, kernel_size = (3, 3), padding = "same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(filters = 128, kernel_size = (3, 3), padding = "same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = MaxPooling2D(pool_size = (2, 2))(x)
x = Flatten(name = "flatten")(x)
x = Dropout(rate = 0.5)(x)
x = Dense(300, activation = "relu", name = "fc1")(x)
x = Dropout(rate = 0.3)(x)
output = Dense(10, activation = "softmax", name = "output")(x)
model = Model(inputs = input_tensor, outputs = output)
return model3. batch size를 변경하면서 fit 수행
b_size = [32, 64, 256, 512]
results = []
evals = []
for i in range(len(b_size)) :
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_images, train_labels = make_zero_to_one(train_images, train_labels)
test_images, test_labels = make_zero_to_one(test_images, test_labels)
train_labels = ohe(train_labels)
test_labels = ohe(test_labels)
(tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels) = \
sper_tr_val(train_images, train_labels, test_images, test_labels, validation_rate = 0.15)
model = create_model()
model.compile(optimizer = Adam(), loss = "categorical_crossentropy", metrics = ["accuracy"])
result = model.fit(tr_images, tr_labels, batch_size = b_size[i], epochs = 30, shuffle = True, \
validation_data= (val_images, val_labels))
eval = model.evaluate(test_images, test_labels, batch_size = b_size[i])
results.append(result)
evals.append(eval)
tf.keras.backend.clear_session()4. results, evals 리스트 확인해보기

5. 그래프로 도시해보기
fig, axs = plt.subplots(figsize = (22, 6), nrows = 1, ncols = 2)
axs[0].plot(results[0].history["val_accuracy"], label = "batch_size = 32")
axs[0].plot(results[1].history["val_accuracy"], label = "batch_size = 64")
axs[0].plot(results[2].history["val_accuracy"], label = "batch_size = 256")
axs[0].plot(results[3].history["val_accuracy"], label = "batch_size = 512")
axs[0].set_title("val_accuracy")
axs[0].set_xlabel("epochs")
axs[0].set_ylabel("accuracy")
axs[0].legend()
axs[1].plot(results[0].history["val_loss"], label = "batch_size = 32")
axs[1].plot(results[1].history["val_loss"], label = "batch_size = 64")
axs[1].plot(results[2].history["val_loss"], label = "batch_size = 256")
axs[1].plot(results[3].history["val_loss"], label = "batch_size = 512")
axs[1].set_title("val_loss")
axs[1].set_xlabel("epochs")
axs[1].set_ylabel("loss")
axs[1].legend()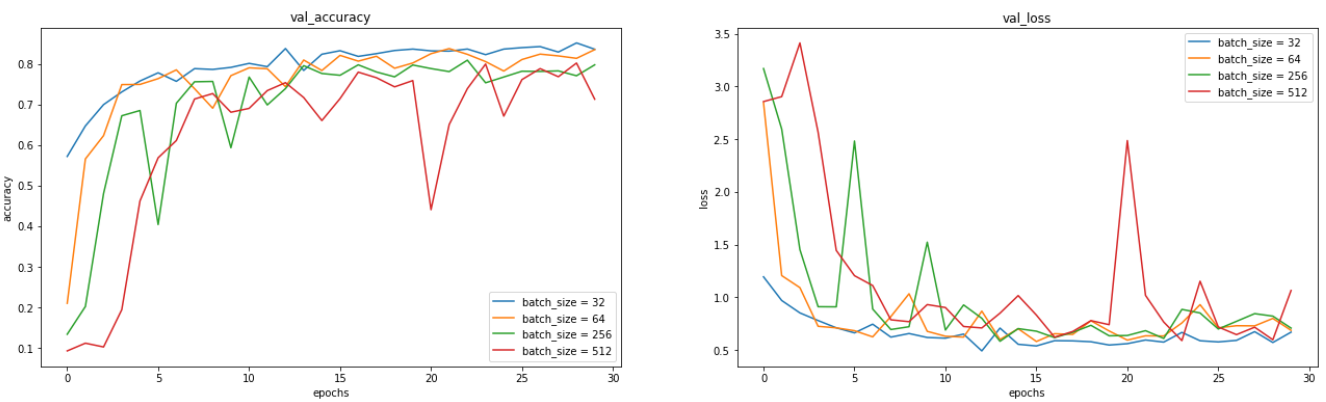
더 작은 배치 사이즈가 상대적으로 더 자주 Gradient를 계산하고 더 자주 weight를 업데이트하므로 보다 정확한 최적화가 가능하다. 논문에서는 8~32의 배치 사이즈를 권고하고 있고, BN(Batch-Normalization)이 적용되어있는 model일 경우에는 더 작은 배치 사이즈를 권고하고 있다.
실제로 배치 사이즈가 작아질수록 효율이 좋아지는 것을 확인할 수 있다.

'Ai > DL' 카테고리의 다른 글
| 성능 향상 using (# of filters, depth) (0) | 2022.02.09 |
|---|---|
| 성능 향상 using callback (0) | 2022.02.09 |
| 성능 향상 using shuffle (0) | 2022.02.09 |
| 성능 향상 using Batch_normalization (0) | 2022.02.07 |
| feature map size 계산 (0) | 2022.02.07 |
'Ai/DL' Related Articles
more




Comments