

목록Ai (33)
UOMOP
 Logistic Regression(다중 분류 로지스틱 회귀)
Logistic Regression(다중 분류 로지스틱 회귀)
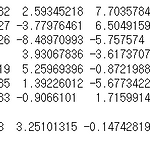
import pandas as pd fish_df = pd.read_csv("http://bit.ly/fish_csv_data") target_data = fish_df["Species"].to_numpy() input_data = fish_df.drop("Species", axis = 1).to_numpy() fish_df 데이터를 불러와서 Species 컬럼은 target, 나머지 컬럼은 input으로 만들어주었다. from sklearn.model_selection import train_test_split # 학습/검증 데이터 분리 train_input, test_input, train_target, test_target = train_test_split(input_data, target_data..
 Logistic Regression(이진 분류 로지스틱 회귀)
Logistic Regression(이진 분류 로지스틱 회귀)
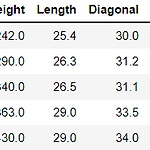
Logistic Regression(로지스틱 회귀)는 분류 알고리즘이다. (회귀 알고리즘이 아니다.) 회귀의 특성으로 임의의 값(z)가 도출되지만, z를 시그모이드 함수를 통해서 확률로 변환하여 양성클래스(1)에 대한 확률을 도출하게 된다. 우선, target 클래스가 2개인 이진 분류 로지스틱 회귀에 대해 알아보도록 한다. import pandas as pd fish_df = pd.read_csv("http://bit.ly/fish_csv_data") fish_df.head() 우선, 웹에서 csv파일을 read_csv메소드를 통해서 불러온다. indexes = (fish_df["Species"] == "Bream") | (fish_df["Species"] == "Smelt") only_bream_sm..
 Multiple Regression(다중 회귀) - 릿지/라쏘
Multiple Regression(다중 회귀) - 릿지/라쏘
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression df = pd.read_csv("https://bit.ly/perch_csv") df.head() perch_all = df.to_numpy() print(perch_all.shape) (56, 3) perch_weight = np.array( [5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 11..
 Linear Regression(선형 회귀)
Linear Regression(선형 회귀)
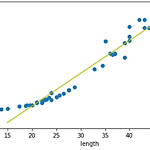
from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(train_input, train_target) lr.predict([[50]]) array([1241.83860323]) 선형 회귀 모델을 호출하고, 이 모델을 통해 훈련을 시켜 50cm의 농어의 무게를 예측해본 결과, 1241.84g가 출력되었다. k-최근접 이웃 회귀 모델보다는 더 이상적인 결과가 나왔음을 확인할 수 있다. print("기울기 : {}\ny절편 : {}".format(lr.coef_, lr.intercept_)) 기울기 : [39.01714496] y절편 : -709.0186449535477 선형 회귀 모델에서는 lr.coef_에 기울기가 ..
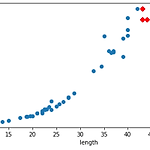 k-최근접 이웃 model의 문제점
k-최근접 이웃 model의 문제점
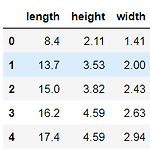
k-최근접 이웃 모델에는 한가지 대표적인 문제점이 있다. import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import mean_absolute_error from sklearn.neighbors import KNeighborsRegressor from sklearn.model_selection import train_test_split perch_length = np.array( [8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7, 23.0, 2..
 농어(perch) 무게 예측 using "k-최근접 이웃 회귀"
농어(perch) 무게 예측 using "k-최근접 이웃 회귀"
지도 학습에는 분류(Classify), 회귀(Regress)가 있다, "분류"는 종류를 분류하는 것이고, 예를 들어서 도미와 빙어의 데이터로 학습을 한 후에, 새로운 샘플에 대해서 도미인지 빙어인지 확인하는 실습이 있었다. "회귀"는 임의의 숫자를 예측하는 것이고, 예를 들어 데이터를 통해서 학습을 한 후에, 새로운 샘플에 대해서 임의의 특징에 대한 값을 예측하는 실습이 있다. k-최근접 이웃 k-최근접 이웃 분류는 실험 샘플의 주변 중 더 많은 target으로 분류시키는 과정이었다면 k-최근점 이웃 회귀는 실험 샘플의 주변의 데이터를 평균을 내어 target값을 예측한다. 1. 농어의 길이, 무게 데이터를 가져오고 각종 module을 호출 import numpy as np import matplotli..