
UOMOP
My model vs VGG16 본문
1. 각종 모듈 호출
import os
import cv2
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, BatchNormalization, Dropout, \
Flatten, Activation, MaxPooling2D, GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.applications import VGG16, ResNet50V2, Xception2. 각종 함수 정의
def make_to_float(images, labels) :
images = np.array(images, dtype=np.float32)
labels = np.array(labels, dtype=np.float32)
return images, labels
def ohe(labels) :
labels = to_categorical(labels)
return labels
def tr_val_test(train_images, train_labels, test_images, test_labels, val_rate) :
tr_images, val_images, tr_labels, val_labels = \
train_test_split(train_images, train_labels, test_size=val_rate)
return (tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels)
def resize_images(images, resize) :
resized_images = np.zeros((images.shape[0], resize, resize, 3))
for i in range(images.shape[0]) :
resized_image = cv2.resize(images[i], (resize, resize))
resized_images[i] = resized_image
return resized_images
def create_pretrained_model(model_name, verbose) :
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
if model_name == "vgg16" :
base_model = VGG16(input_tensor=input_tensor, include_top=False, weights="imagenet")
elif model_name == "resnet50" :
base_model = ResNet50V2(input_tensor=input_tensor, include_top=False, weights="imagenet")
elif model_name == "xception" :
base_model = Xception(input_tensor=input_tensor, include_top=False, weights="imagenet")
bm_output = base_model.output
x = GlobalAveragePooling2D()(bm_output)
if model_name != 'vgg16' :
x = Dropout(rate=0.5)(x)
x = Dense(50, activation="relu")(x)
output = Dense(10, activation="softmax")(x)
model = Model(inputs=input_tensor, outputs=output)
if verbose == True :
model.summary()
return model
def create_my_model(verbose) :
input_tensor = Input(shape = (32, 32, 3))
x = Conv2D(filters=64, kernel_size=(3, 3), padding="same")(input_tensor)
x = BatchNormalization()(x)
x = Activation("relu")(x)
num_filter = [64, 128, 128, 256, 256, 512]
n = 1
for i in num_filter :
x = Conv2D(filters=i, kernel_size=(3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
if n%2 != 0 :
x = MaxPooling2D(pool_size=(2, 2))(x)
n+=1
x = GlobalAveragePooling2D()(x)
x = Dropout(rate=0.5)(x)
x = Dense(50, activation="relu")(x)
x = Dropout(rate=0.2)(x)
output = Dense(10, activation="softmax")(x)
model = Model(inputs=input_tensor, outputs=output)
if verbose==True:
model.summary()
return model
def compare_acc(result_1, result_2) :
fig, axs = plt.subplots(figsize=(20, 5), nrows=1, ncols=2)
axs[0].plot(result_1.history["accuracy"], label="tr_acc", linewidth=4)
axs[0].plot(result_1.history["val_accuracy"], label="val_acc", linewidth=4)
axs[0].set_title("My model")
axs[0].set_xlabel("epochs")
axs[0].set_ylabel("accuracy")
axs[0].legend()
axs[1].plot(result_2.history["accuracy"], label="tr_acc", linewidth=4)
axs[1].plot(result_2.history["val_accuracy"], label="val_acc", linewidth=4)
axs[1].set_title("Pretrained model")
axs[1].set_xlabel("epochs")
axs[1].set_ylabel("accuracy")
axs[1].legend()
def compare_loss(result_1, result_2) :
fig, axs = plt.subplots(figsize=(20, 5), nrows=1, ncols=2)
axs[0].plot(result_1.history["loss"], label="tr_loss", linewidth=4)
axs[0].plot(result_1.history["val_loss"], label="val_loss", linewidth=4)
axs[0].set_title("My model")
axs[0].set_xlabel("epochs")
axs[0].set_ylabel("loss")
axs[0].legend()
axs[1].plot(result_2.history["loss"], label="tr_loss", linewidth=4)
axs[1].plot(result_2.history["val_loss"], label="val_loss", linewidth=4)
axs[1].set_title("Pretrained model")
axs[1].set_xlabel("epochs")
axs[1].set_ylabel("loss")
axs[1].legend()3. 데이터 전처리 및 shape 확인
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_images, train_labels = make_to_float(train_images, train_labels)
test_images, test_labels = make_to_float(test_images, test_labels)
train_labels = ohe(train_labels)
test_labels = ohe(test_labels)
(tr_images, tr_labels), (val_images, val_labels), (test_images, test_labels) = \
tr_val_test(train_images, train_labels, test_images, test_labels, val_rate=0.15)
print("train data's shape : \n{}, {}\n".format(tr_images.shape, tr_labels.shape))
print("validation data's shape : \n{}, {}\n".format(val_images.shape, val_labels.shape))
print("test data's shape : \n{}, {}".format(test_images.shape, test_labels.shape))
4. ImageDataGenerator
BATCH_SIZE=64
tr_generator = ImageDataGenerator(horizontal_flip=True, rescale=1/255.0)
val_generator = ImageDataGenerator(rescale=1/255.0)
test_generator = ImageDataGenerator(rescale=1/255.0)
flow_tr_gen = tr_generator.flow(tr_images, tr_labels, batch_size=BATCH_SIZE, shuffle=True)
flow_val_gen = val_generator.flow(val_images, val_labels, batch_size=BATCH_SIZE, shuffle=False)
flow_test_gen = test_generator.flow(test_images, test_labels, batch_size=BATCH_SIZE, shuffle=False)5. callback
rlr_cb = ReduceLROnPlateau(monitor="val_loss", mode="min", factor=0.2, patience=5, verbose=True)
ely_cb = EarlyStopping(monitor="val_loss", mode="min", patience=10, verbose=True)6. my model 생성, 설정, 학습
model_mine = create_my_model(verbose=True)
model_mine.compile(optimizer=Adam(learning_rate=0.001), loss="categorical_crossentropy", metrics=["accuracy"])
result_mine = model_mine.fit(flow_tr_gen, epochs=40, validation_data=flow_val_gen, callbacks=[rlr_cb, ely_cb])7. VGG16을 위한 data resize
tr_images = resize_images(tr_images, resize=64)
val_images = resize_images(val_images, resize=64)
test_images = resize_images(test_images, resize=64)
print("#### 크기를 64x64로 resize한 후 shape ####\n")
print("train data's shape : \n{}, {}\n".format(tr_images.shape, tr_labels.shape))
print("validation data's shape : \n{}, {}\n".format(val_images.shape, val_labels.shape))
print("test data's shape : \n{}, {}".format(test_images.shape, test_labels.shape))
8. VGG16 생성, 설정, 학습
IMAGE_SIZE=64
model_vgg16 = create_pretrained_model(model_name = "vgg16", verbose = True)
model_vgg16.compile(optimizer=Adam(learning_rate=0.001), loss="categorical_crossentropy", metrics=["accuracy"])
result_vgg16 = model_vgg16.fit(flow_tr_gen, epochs=40, validation_data=flow_val_gen, callbacks=[rlr_cb, ely_cb])9. accuracy 비교
compare_acc(result_mine, result_vgg16)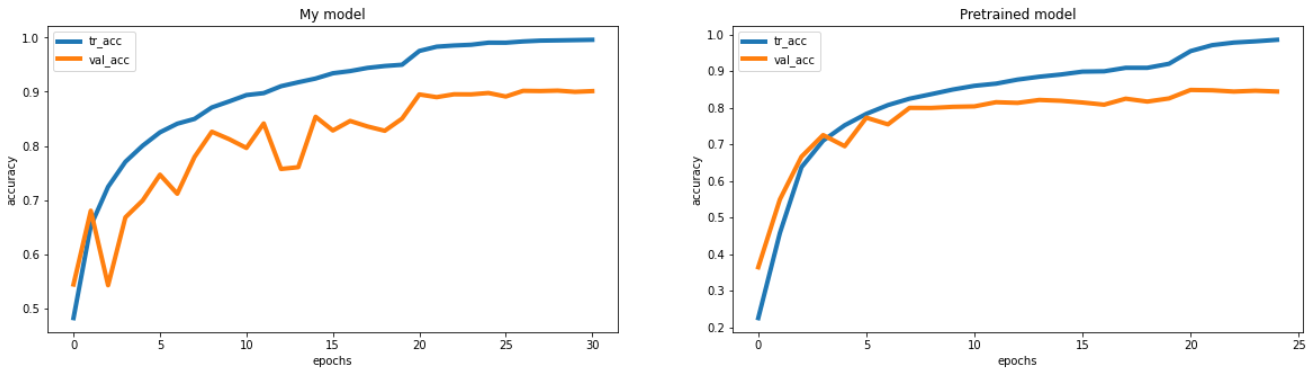
10. loss 비교
compare_loss(result_mine, result_vgg16)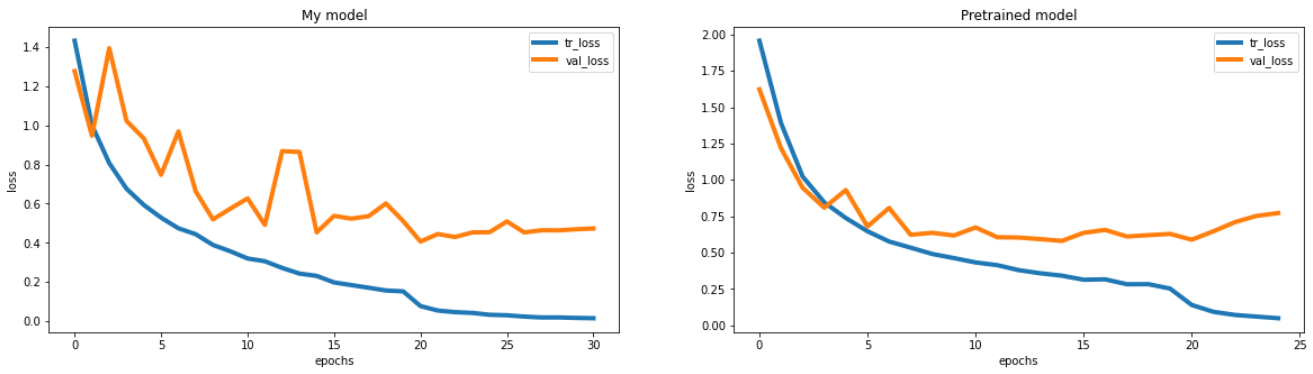

'Ai > DL' 카테고리의 다른 글
| Performance Comparison according to Data Augmentation (0) | 2022.02.13 |
|---|---|
| Pixel value "Normalization" (0) | 2022.02.10 |
| Data Augmentation(픽셀 기반) (0) | 2022.02.10 |
| Data Augmentation(공간 기반) (0) | 2022.02.10 |
| Data Augmentation(데이터 증강) 기본 (0) | 2022.02.10 |
'Ai/DL' Related Articles
more




Comments