

UOMOP
PSNR Comparison (Compression Ratio : [1/96, 1/24, 1/6], PatchSize : 2) 본문
Main
PSNR Comparison (Compression Ratio : [1/96, 1/24, 1/6], PatchSize : 2)
Happy PinGu 2024. 3. 19. 20:38import matplotlib.pyplot as plt
# 데이터 정의
X = [0, 15, 30]
# 각 선택 메커니즘별 데이터, MR = 100% 제외
Y_low = [
[15.752, 18.992, 19.364], # MR = 0%
[15.761, 18.909, 19.272], # MR = 25%
[15.718, 18.706, 19.015], # MR = 50%
[15.572, 18.021, 18.232] # MR = 75%
]
Y_high = [
[15.773, 18.986, 19.371], # MR = 0%
[15.763, 18.903, 19.264], # MR = 25%
[15.685, 18.683, 19.012], # MR = 50%
[15.532, 17.897, 18.102] # MR = 75%
]
Y_gaussian = [
[15.795, 18.989, 19.363], # MR = 0%
[15.723, 18.881, 19.243], # MR = 25%
[15.713, 18.634, 18.945], # MR = 50%
[15.448, 17.907, 18.111] # MR = 75%
]
# 선 스타일 및 색상 설정 (Gaussian Selection을 초록색으로 변경)
styles = ['-', '--', '-.', ':']
colors = ['blue', 'red', 'green'] # 마젠타 -> 초록으로 변경
labels = ['MR = 0%', 'MR = 25%', 'MR = 50%', 'MR = 75%'] # MR = 100% 레이블 제외
selections = ['Low attention Selection', 'High attention Selection', 'Gaussian Selection']
data_groups = [Y_low, Y_high, Y_gaussian]
import matplotlib.pyplot as plt
from collections import OrderedDict
# 데이터와 기타 설정은 이전과 동일합니다...
plt.figure(figsize=(10, 6))
for data_group, color, selection in zip(data_groups, colors, selections):
for Y, style, label in zip(data_group, styles, labels):
plt.plot(X, Y, style, color=color, label=f'{selection}, {label}')
plt.title('Compression Ratio : 1/96, Patch Size : 2')
plt.xlabel('SNR(dB)')
plt.ylabel('PSNR')
plt.ylim(15, 20)
plt.grid(True)
# 범례 위치 조정을 위한 핸들러와 레이블 가져오기
handles, labels = plt.gca().get_legend_handles_labels()
# 범례 항목을 중복 없이 한 번만 표시하기 위해, unique한 범례만 추출
unique = OrderedDict(zip(labels, handles))
plt.legend(unique.values(), unique.keys(), loc='upper right', bbox_to_anchor=(1.4, 1))
plt.tight_layout()
plt.show()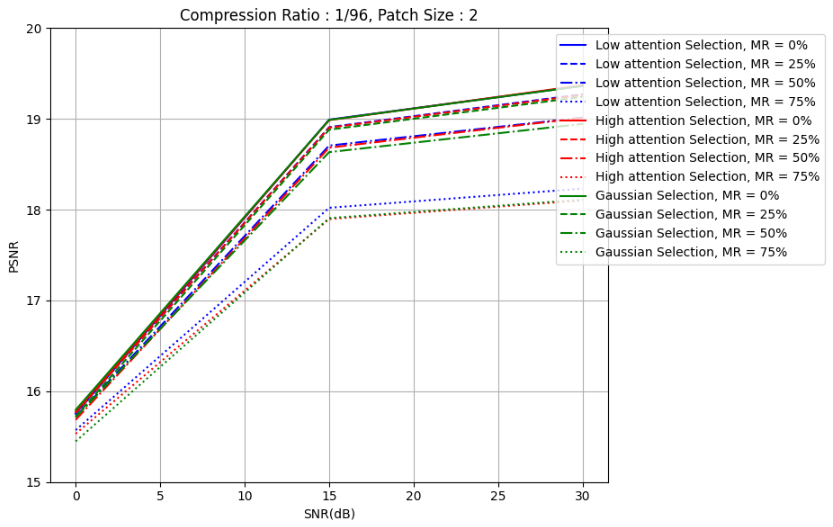
import matplotlib.pyplot as plt
# 데이터 정의
X = [0, 15, 30]
# 각 선택 메커니즘별 데이터, MR = 100% 제외
Y_low = [
[18.129, 22.806, 23.461], # MR = 0%
[18.098, 22.326, 22.878], # MR = 25%
[17.874, 21.349, 21.757], # MR = 50%
[17.349, 19.243, 19.438] # MR = 75%
]
Y_high = [
[18.177, 22.796, 23.464], # MR = 0%
[18.121, 22.354, 22.902], # MR = 25%
[17.937, 21.333, 21.718], # MR = 50%
[17.278, 19.054, 19.257] # MR = 75%
]
Y_gaussian = [
[18.183, 22.809, 23.474], # MR = 0%
[18.103, 22.292, 22.858], # MR = 25%
[17.849, 21.223, 21.676], # MR = 50%
[17.213, 19.238, 19.481] # MR = 75%
]
# 선 스타일 및 색상 설정 (Gaussian Selection을 초록색으로 변경)
styles = ['-', '--', '-.', ':']
colors = ['blue', 'red', 'green'] # 마젠타 -> 초록으로 변경
labels = ['MR = 0%', 'MR = 25%', 'MR = 50%', 'MR = 75%'] # MR = 100% 레이블 제외
selections = ['Low attention Selection', 'High attention Selection', 'Gaussian Selection']
data_groups = [Y_low, Y_high, Y_gaussian]
import matplotlib.pyplot as plt
from collections import OrderedDict
# 데이터와 기타 설정은 이전과 동일합니다...
plt.figure(figsize=(10, 6))
for data_group, color, selection in zip(data_groups, colors, selections):
for Y, style, label in zip(data_group, styles, labels):
plt.plot(X, Y, style, color=color, label=f'{selection}, {label}')
plt.title('Compression Ratio : 1/24, Patch Size : 2')
plt.xlabel('SNR(dB)')
plt.ylabel('PSNR')
plt.ylim(16, 25)
plt.grid(True)
# 범례 위치 조정을 위한 핸들러와 레이블 가져오기
handles, labels = plt.gca().get_legend_handles_labels()
# 범례 항목을 중복 없이 한 번만 표시하기 위해, unique한 범례만 추출
unique = OrderedDict(zip(labels, handles))
plt.legend(unique.values(), unique.keys(), loc='upper right', bbox_to_anchor=(1.4, 1))
plt.tight_layout()
plt.show()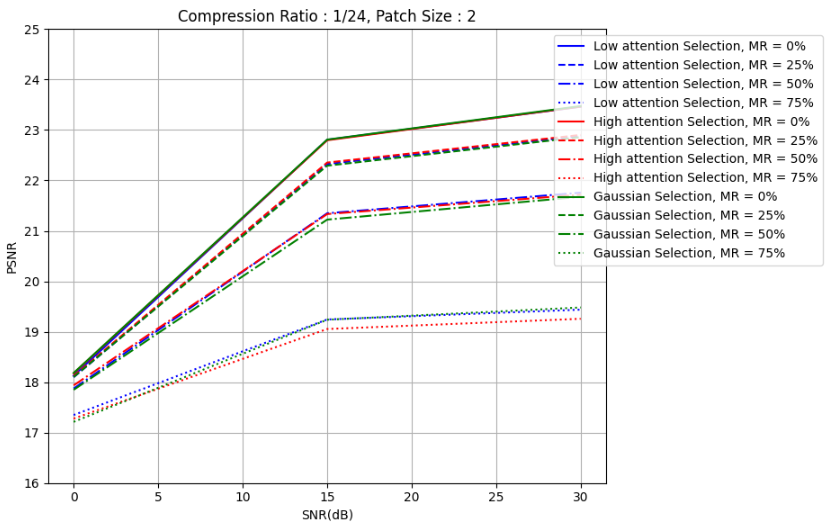
import matplotlib.pyplot as plt
# 데이터 정의
X = [0, 15, 30]
# 각 선택 메커니즘별 데이터, MR = 100% 제외
Y_low = [
[21.26, 28.427, 29.693], # MR = 0%
[20.949, 25.819, 26.665], # MR = 25%
[20.242, 22.764, 22.935], # MR = 50%
[18.641, 19.373, 19.532] # MR = 75%
]
Y_high = [
[21.212, 28.478, 29.963], # MR = 0%
[20.937, 25.949, 26.684], # MR = 25%
[20.206, 22.715, 22.896], # MR = 50%
[18.404, 19.209, 19.275] # MR = 75%
]
Y_gaussian = [
[21.347, 28.538, 29.857], # MR = 0%
[20.832, 25.673, 26.201], # MR = 25%
[20.036, 22.554, 22.841], # MR = 50%
[18.482, 19.617, 19.743] # MR = 75%
]
# 선 스타일 및 색상 설정 (Gaussian Selection을 초록색으로 변경)
styles = ['-', '--', '-.', ':']
colors = ['blue', 'red', 'green'] # 마젠타 -> 초록으로 변경
labels = ['MR = 0%', 'MR = 25%', 'MR = 50%', 'MR = 75%'] # MR = 100% 레이블 제외
selections = ['Low attention Selection', 'High attention Selection', 'Gaussian Selection']
data_groups = [Y_low, Y_high, Y_gaussian]
import matplotlib.pyplot as plt
from collections import OrderedDict
# 데이터와 기타 설정은 이전과 동일합니다...
plt.figure(figsize=(10, 6))
for data_group, color, selection in zip(data_groups, colors, selections):
for Y, style, label in zip(data_group, styles, labels):
plt.plot(X, Y, style, color=color, label=f'{selection}, {label}')
plt.title('Compression Ratio : 1/6, Patch Size : 2')
plt.xlabel('SNR(dB)')
plt.ylabel('PSNR')
plt.ylim(18, 30)
plt.grid(True)
# 범례 위치 조정을 위한 핸들러와 레이블 가져오기
handles, labels = plt.gca().get_legend_handles_labels()
# 범례 항목을 중복 없이 한 번만 표시하기 위해, unique한 범례만 추출
unique = OrderedDict(zip(labels, handles))
plt.legend(unique.values(), unique.keys(), loc='upper right', bbox_to_anchor=(1.4, 1))
plt.tight_layout()
plt.show()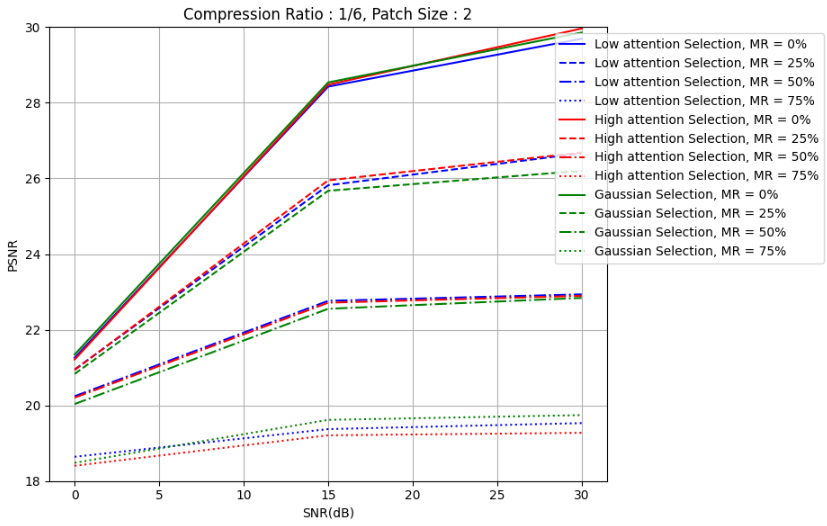
'Main' 카테고리의 다른 글
| Chessboard_masking (0) | 2024.04.08 |
|---|---|
| Mean_far_selection (0) | 2024.04.01 |
| Gaussian Selection Performance (CR : 1/6, 1/24, 1/96) (PS : 2) (0) | 2024.03.19 |
| High Attention Selection Performance (CR : 1/6, 1/24, 1/96) (PS : 2) (0) | 2024.03.18 |
| Low Attention Selection Performance (CR : 1/6, 1/24, 1/96) (PS : 2) (1) | 2024.03.15 |
'Main' Related Articles
more




Comments