
UOMOP
전처리 과정 中 Scaling의 중요성 본문
1. 데이터를 가지고 와서 input data, target data로 분류
import numpy as np
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
fish_length = bream_length + smelt_length
fish_weight = bream_weight + smelt_weight
fish_data = np.column_stack((fish_length, fish_weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
print(fish_data)
print("")
print(fish_target)


2. 학습 및 평가
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
train_input, test_input, train_target, test_target = train_test_split(fish_data,
fish_target, test_size = 0.2, stratify = fish_target, random_state = 42)
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)1.0
3. 새로운 data를 통해서 결과를 예측해보기
print(kn.predict([[25, 150]]))[0.]
distances, indexes = kn.kneighbors([[25, 150]])
print("(25, 150)과 가장 가까운 점 5개와의 거리 : {}\n".format(distances))
print("(25, 150)과 가장 가까운 점 5개와의 인덱스 : {}".format(indexes))(25, 150)과 가장 가까운 점 5개와의 거리 : [[150.2675072 150.27996089 150.3795216 150.4543032 150.48510969]]
(25, 150)과 가장 가까운 점 5개와의 인덱스 : [[30 35 4 15 24]]
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker = "^")
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker = "D", color = "r")
plt.xlabel("length")
plt.ylabel("weight")
plt.show()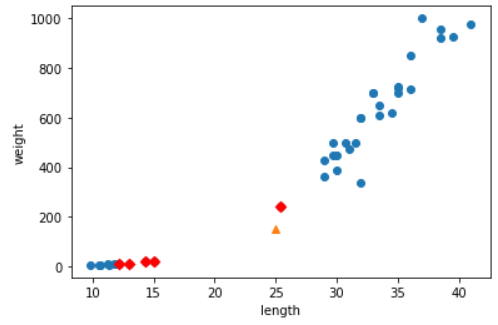
[25, 150]인 생선의 종을 예측해본 결과 0(빙어)이 나왔다.
하지만 그래프로 도시해본 결과, 1(도미)가 나와야할 것 같다. 위와 같은 문제는 그래프 scale의 문제 때문이다.
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker = "^")
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker = "D", color = "r")
plt.xlim(0, 1000)
plt.xlabel("length")
plt.ylabel("weight")
plt.show()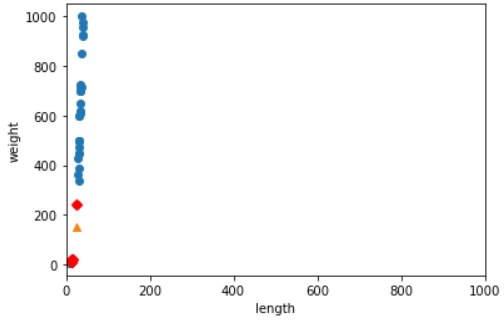
x, y축의 scale을 같게 해 주면 왜 [25, 150] 생선이 빙어로 예측했는지 알 수 있다. 다음과 같이 특성의 scale을 맞춰주는 작업이 필요한 ML알고리즘이 있다.
스케일을 맞춰주기 위해 train_input data를 표준 점수로 바꿔주자!
4. Scaling : 표준점수(std)
mean = np.mean(train_input, axis = 0)
std = np.std(train_input, axis = 0)
print("mean(평균) : {}\nstd(표준편차) : {}".format(mean, std))mean(평균) : [ 27.24871795 454.54871795]
std(표준편차) : [ 10.07499753 327.27251866]
train_scaled = (train_input - mean) / std
new = ([25, 150] - mean) / std
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker = "^")
plt.xlabel("length")
plt.ylabel("weight")
plt.show()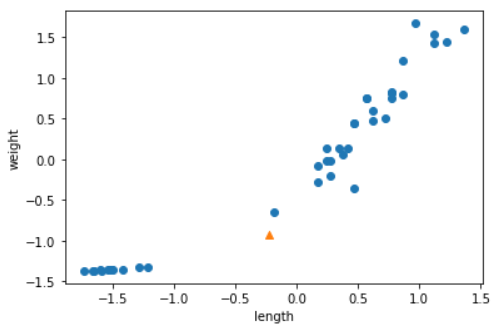
test_scaled = (test_input - mean) / std
kn.fit(train_scaled, train_target)
kn.score(test_scaled, test_target)1.0
print(kn.predict([new]))[1.]
distances, indexes = kn.kneighbors([new])
print("(25, 150)과 가장 가까운 점 5개와의 거리 : {}\n".format(distances))
print("(25, 150)과 가장 가까운 점 5개와의 인덱스 : {}".format(indexes))(25, 150)과 가장 가까운 점 5개와의 거리 : [[0.28390108 0.7623722 0.88547747 0.90541553 0.94318771]]
(25, 150)과 가장 가까운 점 5개와의 인덱스 : [[ 1 19 31 7 33]]
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker = "^")
plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], marker = "D", color = "r")
plt.xlabel("length")
plt.ylabel("weight")
plt.show()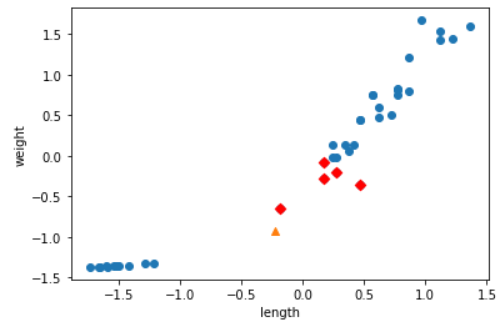
train_input, test_input을 표준점수로 scaling을 해주고 난 후, 그래프를 확인해보았다.
실제로 scaling을 해주고 난 후에는 가장 가까운 거리에 점들이 바뀌었고 결과 값도 달라지는 것을 확인하였다.

'Ai > ML' 카테고리의 다른 글
| Linear Regression(선형 회귀) (0) | 2022.01.25 |
|---|---|
| k-최근접 이웃 model의 문제점 (0) | 2022.01.25 |
| 농어(perch) 무게 예측 using "k-최근접 이웃 회귀" (0) | 2022.01.24 |
| KNeighborsClassifier(k-최근접 이웃)의 기본 (0) | 2022.01.23 |
| 타이타닉 생존자 예측 using DecisionTreeClassifier (0) | 2022.01.15 |
'Ai/ML' Related Articles
more




Comments