
UOMOP
타이타닉 생존자 예측 using DecisionTreeClassifier 본문
1. csv파일을 불러오기
import numpy as np
import pandas as pd
titanic_df = pd.read_csv("titanic_train.csv")
titanic_df.head(3)
print("\n ### titanic_train.csv Data ### \n")
print("-"*40)
print(titanic_df.info())
# info()함수는 컬럼 별 "이름", "# of Null","data type"을 보여준다### titanic_train.csv Data ###
----------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 891 non-null object
11 Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
2. NULL 칼럼들에 대한 처리
- null은 머신러닝 알고리즘에서 허용이 안되서 대체 해줘야한다.
- 우선 Age/Cabin/Embarked 칼럼들에 NULL이 존재하므로 fillna() 사용
titanic_df["Age"].fillna(titanic_df["Age"].mean(), inplace = True)
titanic_df["Cabin"].fillna("N", inplace = True)
titanic_df["Embarked"].fillna("N", inplace = True)
print(titanic_df.info())
print("-" * 40)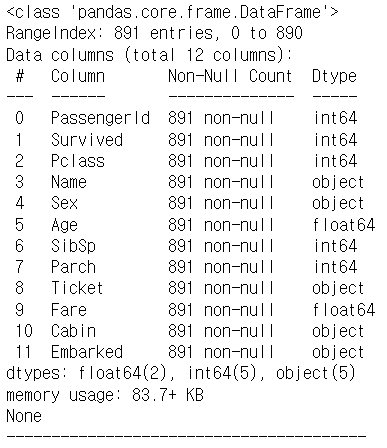
print("데이터 세트의 NULL 갯수 : \n\n{}".format(titanic_df.isnull().sum()))데이터 세트의 NULL 갯수 :
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64
3. 카테고리성 object의 value 확인
- 우선 Sex, Cabin, Embarked의 value들을 확인해보자
print("'Sex' Value의 분포 : \n\n{}".format(titanic_df["Sex"].value_counts()))
print("-" * 40)
print("'Cabin' Value의 분포 : \n\n{}".format(titanic_df["Cabin"].value_counts()))
print("-" * 40)
print("'Embarked' Value의 분포 : \n\n{}".format(titanic_df["Embarked"].value_counts()))
- 확인 결과, "Cabin"의 카테고리 종류가 너무 많다.
- 앞에 알파벳으로만 분류해보도록 하자.
titanic_df["Cabin"] = titanic_df["Cabin"].str[0]
print("수정 후 'Cabin' Value 분포 : \n\n{}".format(titanic_df["Cabin"].value_counts()))
4. 카테고리성 object의 label encoding
from sklearn import preprocessing
def encode_features(dataDF) :
features = ["Cabin", "Sex", "Embarked"]
for feature in features :
le = preprocessing.LabelEncoder()
le = le.fit(dataDF[feature])
dataDF[feature] = le.transform(dataDF[feature])
return dataDF
titanic_df = encode_features(titanic_df)
titanic_df.head(5)
- Sex, Cabin, Embarked가 모두 label encoding된 것을 확인할 수 있다.
5. 불필요한 속성들 제거
- 생사여부를 예측하는데 PassengerID나 이름, 티켓이름은 중요하지 않으므로 전부 제거해준다.
titanic_df.drop(["PassengerId", "Name", "Ticket"], axis = 1, inplace = True)
titanic_df.head(4)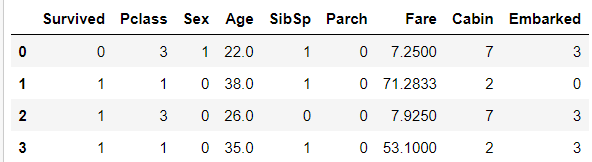
6. 학습/검증 데이터를 추출
from sklearn.model_selection import train_test_split
y_titanic_df = titanic_df["Survived"]
X_titanic_df = titanic_df.drop("Survived", axis = 1)
# feature 데이터와 label 데이터를 먼저 분리한다
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df,
test_size = 0.2, random_state = 11)7. 교차검증 하지 않고 학습시켜 예측 정확도 확인해보기
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 결정트리를 위한 사이킷런 Classifier 클래스 생성
dt_clf = DecisionTreeClassifier(random_state=11)
# DecisionTreeClassifier 학습/예측/평가
dt_clf.fit(X_train , y_train)
dt_pred = dt_clf.predict(X_test)
print('DecisionTreeClassifier 정확도: {0:.4f}'.format(accuracy_score(y_test, dt_pred)))DecisionTreeClassifier 정확도: 0.7877
7-1. cross_val_score을 통해 교차검증
- 학습용 데이터와 검증용 데이터를 나누어서 훈련을 시켜주게 되면 검증용 데이터로는 학습이 될수 없는 상황이다.
- 모든 데이터를 활용하는 것이 좋기 때문에 교차검증을 사용하게 된다.
from sklearn.model_selection import cross_val_score
dt_clf = DecisionTreeClassifier(random_state=11) # 러닝 모델 호출
scores = cross_val_score(dt_clf, X_titanic_df, y_titanic_df, cv = 5) # 5폴드 교차검증
print(scores)
print("\n보기 좋게 만들어보자\n")
for n in range(len(scores)):
print("{}차 교차검증 예측정확도 : {:.4f}".format(n+1, scores[n]))
print("-" * 40)
print("5차 교차검증 예측정확도 평균 : {:.4f}".format(scores.mean()))
7-2. GridSearchCV로 HyperParameter 튜닝과 교차검증을 동시에!
- 우선 섞자
titanic_df = titanic_df.sample(frac = 1, random_state = 0)
titanic_df.head()
from sklearn.model_selection import GridSearchCV
dt_clf = DecisionTreeClassifier(random_state=11) # 러닝 모델 호출
parameters = {'max_depth':[2,3,5,10], 'min_samples_split':[2,3,5], 'min_samples_leaf':[1,5,8]}
X_train_df = titanic_df.drop("Survived", axis = 1)
y_train_df = titanic_df["Survived"]
grid_dclf = GridSearchCV(dt_clf, param_grid = parameters, scoring = "accuracy", cv = 5)
# 학습
grid_dclf.fit(X_train, y_train)
print('GridSearchCV 최적 하이퍼 파라미터 :',grid_dclf.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dclf.best_score_))
best_dclf = grid_dclf.best_estimator_
# GridSearchCV의 최적 하이퍼 파라미터로 학습된 Estimator로 예측 및 평가 수행.
print(best_dclf)
prepre = best_dclf.predict(X_test)
accuracy = accuracy_score(y_test, prepre)
print('테스트 세트에서의 DecisionTreeClassifier 정확도 : {0:.4f}'.format(accuracy))GridSearchCV 최적 하이퍼 파라미터 : {'max_depth': 3, 'min_samples_leaf': 5, 'min_samples_split': 2}
GridSearchCV 최고 정확도: 0.7992
DecisionTreeClassifier(max_depth=3, min_samples_leaf=5, random_state=11)
테스트 세트에서의 DecisionTreeClassifier 정확도 : 0.8715
'Ai > ML' 카테고리의 다른 글
| Linear Regression(선형 회귀) (0) | 2022.01.25 |
|---|---|
| k-최근접 이웃 model의 문제점 (0) | 2022.01.25 |
| 농어(perch) 무게 예측 using "k-최근접 이웃 회귀" (0) | 2022.01.24 |
| 전처리 과정 中 Scaling의 중요성 (0) | 2022.01.23 |
| KNeighborsClassifier(k-최근접 이웃)의 기본 (0) | 2022.01.23 |
'Ai/ML' Related Articles
more




Comments