

UOMOP
DDPM cifar10 Simple Unet 본문
import torch
import torchvision
import matplotlib.pyplot as plt
import os
import time
import math
import torch
import torchvision
from torchvision.transforms import ToTensor, Compose, Normalize
import torch.nn as nn
from torchvision.utils import make_grid
import numpy as np
import torch.nn.functional as F
device = 'cuda' if torch.cuda.is_available() else 'cpu'
def linear_beta_schedule(timesteps, start=0.0001, end=0.02):
return torch.linspace(start, end, timesteps)
def get_index_from_list(vals, t, x_shape):
"""
Returns a specific index t of a passed list of values vals
while considering the batch dimension.
"""
# vals = [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]
# t = [2, 1, 3]
# 로 주어져있다면 3, 7, 14를 추출함
batch_size = t.shape[0]
out = vals.gather(-1, t.cpu())
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
def forward_diffusion_sample(x_0, t, device="cpu"):
"""
Takes an image and a timestep as input and
returns the noisy version of it
"""
noise = torch.randn_like(x_0)
sqrt_alphas_cumprod_t = get_index_from_list(sqrt_alphas_cumprod, t, x_0.shape)
sqrt_one_minus_alphas_cumprod_t = get_index_from_list(
sqrt_one_minus_alphas_cumprod, t, x_0.shape
)
# mean + variance
return sqrt_alphas_cumprod_t.to(device) * x_0.to(device) \
+ sqrt_one_minus_alphas_cumprod_t.to(device) * noise.to(device), noise.to(device)
# Define beta schedule
T = 300
betas = linear_beta_schedule(timesteps=T)
# Pre-calculate different terms for closed form
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
from torchvision import transforms
from torch.utils.data import DataLoader
import numpy as np
IMG_SIZE = 32
BATCH_SIZE = 64
def load_transformed_dataset():
data_transforms = [
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(), # Scales data into [0,1]
transforms.Lambda(lambda t: (t * 2) - 1) # Scale between [-1, 1]
]
data_transform = transforms.Compose(data_transforms)
train = torchvision.datasets.CIFAR10('data', train=True, download=True, transform=Compose([ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]))
test = torchvision.datasets.CIFAR10('data', train=False, download=True, transform=Compose([ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]))
return torch.utils.data.ConcatDataset([train, test])
def show_tensor_image(image):
reverse_transforms = transforms.Compose([
transforms.Lambda(lambda t: (t + 1) / 2),
transforms.Lambda(lambda t: t.permute(1, 2, 0)), # CHW to HWC
transforms.Lambda(lambda t: t * 255.),
transforms.Lambda(lambda t: t.numpy().astype(np.uint8)),
transforms.ToPILImage(),
])
# Take first image of batch
if len(image.shape) == 4:
image = image[0, :, :, :]
plt.imshow(reverse_transforms(image))
data = load_transformed_dataset()
dataloader = DataLoader(data, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
from torch import nn
import math
class Block(nn.Module):
def __init__(self, in_ch, out_ch, time_emb_dim, up=False):
super().__init__()
self.time_mlp = nn.Linear(time_emb_dim, out_ch)
if up:
self.conv1 = nn.Conv2d(2*in_ch, out_ch, 3, padding=1)
self.transform = nn.ConvTranspose2d(out_ch, out_ch, 4, 2, 1)
else:
self.conv1 = nn.Conv2d(in_ch, out_ch, 3, padding=1)
self.transform = nn.Conv2d(out_ch, out_ch, 4, 2, 1)
self.conv2 = nn.Conv2d(out_ch, out_ch, 3, padding=1)
self.bnorm1 = nn.BatchNorm2d(out_ch)
self.bnorm2 = nn.BatchNorm2d(out_ch)
self.relu = nn.ReLU()
def forward(self, x, t, ):
# First Conv
h = self.bnorm1(self.relu(self.conv1(x)))
# Time embedding
time_emb = self.relu(self.time_mlp(t))
# Extend last 2 dimensions
time_emb = time_emb[(..., ) + (None, ) * 2]
# Add time channel
h = h + time_emb
# Second Conv
h = self.bnorm2(self.relu(self.conv2(h)))
# Down or Upsample
return self.transform(h)
class SinusoidalPositionEmbeddings(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, time):
device = time.device
half_dim = self.dim // 2
embeddings = math.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
embeddings = time[:, None] * embeddings[None, :]
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
class SimpleUnet(nn.Module):
"""
A simplified variant of the Unet architecture.
"""
def __init__(self):
super().__init__()
image_channels = 3
down_channels = (64, 128, 256, 512, 1024)
up_channels = (1024, 512, 256, 128, 64)
out_dim = 3
time_emb_dim = 32
# Time embedding
self.time_mlp = nn.Sequential(
SinusoidalPositionEmbeddings(time_emb_dim),
nn.Linear(time_emb_dim, time_emb_dim),
nn.ReLU()
)
# Initial projection
self.conv0 = nn.Conv2d(image_channels, down_channels[0], 3, padding=1)
# Downsample
self.downs = nn.ModuleList([Block(down_channels[i], down_channels[i+1], \
time_emb_dim) \
for i in range(len(down_channels)-1)])
# Upsample
self.ups = nn.ModuleList([Block(up_channels[i], up_channels[i+1], \
time_emb_dim, up=True) \
for i in range(len(up_channels)-1)])
# Edit: Corrected a bug found by Jakub C (see YouTube comment)
self.output = nn.Conv2d(up_channels[-1], out_dim, 1)
def forward(self, x, timestep):
# Embedd time
t = self.time_mlp(timestep)
# Initial conv
x = self.conv0(x)
# Unet
residual_inputs = []
for down in self.downs:
x = down(x, t)
residual_inputs.append(x)
for up in self.ups:
residual_x = residual_inputs.pop()
# Add residual x as additional channels
x = torch.cat((x, residual_x), dim=1)
x = up(x, t)
return self.output(x)
model = SimpleUnet()
print("Num params: ", sum(p.numel() for p in model.parameters()))
def get_loss(model, x_0, t):
x_noisy, noise = forward_diffusion_sample(x_0, t, device)
noise_pred = model(x_noisy, t)
return F.l1_loss(noise, noise_pred)
@torch.no_grad()
def sample_timestep(x, t):
"""
Calls the model to predict the noise in the image and returns
the denoised image.
Applies noise to this image, if we are not in the last step yet.
"""
betas_t = get_index_from_list(betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = get_index_from_list(
sqrt_one_minus_alphas_cumprod, t, x.shape
)
sqrt_recip_alphas_t = get_index_from_list(sqrt_recip_alphas, t, x.shape)
# Call model (current image - noise prediction)
model_mean = sqrt_recip_alphas_t * (
x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t
)
posterior_variance_t = get_index_from_list(posterior_variance, t, x.shape)
if t == 0:
# As pointed out by Luis Pereira (see YouTube comment)
# The t's are offset from the t's in the paper
return model_mean
else:
noise = torch.randn_like(x)
return model_mean + torch.sqrt(posterior_variance_t) * noise
@torch.no_grad()
def sample_plot_image():
# Sample noise
img_size = IMG_SIZE
img = torch.randn((1, 3, img_size, img_size), device=device)
plt.figure(figsize=(15, 15))
plt.axis('off')
num_images = 10
stepsize = int(T / num_images)
for i in range(0, T)[::-1]:
t = torch.full((1,), i, device=device, dtype=torch.long)
img = sample_timestep(img, t)
# Edit: This is to maintain the natural range of the distribution
img = torch.clamp(img, -1.0, 1.0)
if i % stepsize == 0:
plt.subplot(1, num_images, int(i / stepsize) + 1)
show_tensor_image(img.detach().cpu())
plt.show()
from torch.optim import Adam
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
optimizer = Adam(model.parameters(), lr=0.001)
epochs = 1000 # Try more!
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
t = torch.randint(0, T, (BATCH_SIZE,), device=device).long()
loss = get_loss(model, batch[0], t)
loss.backward()
optimizer.step()
if epoch % 5 == 0 and step == 0:
print(f"Epoch {epoch} | step {step:03d} Loss: {loss.item()} ")
sample_plot_image()
if (epoch + 1) % 10 == 0:
save_path = str(epoch + 1) + ".pth"
torch.save(model.state_dict(), save_path)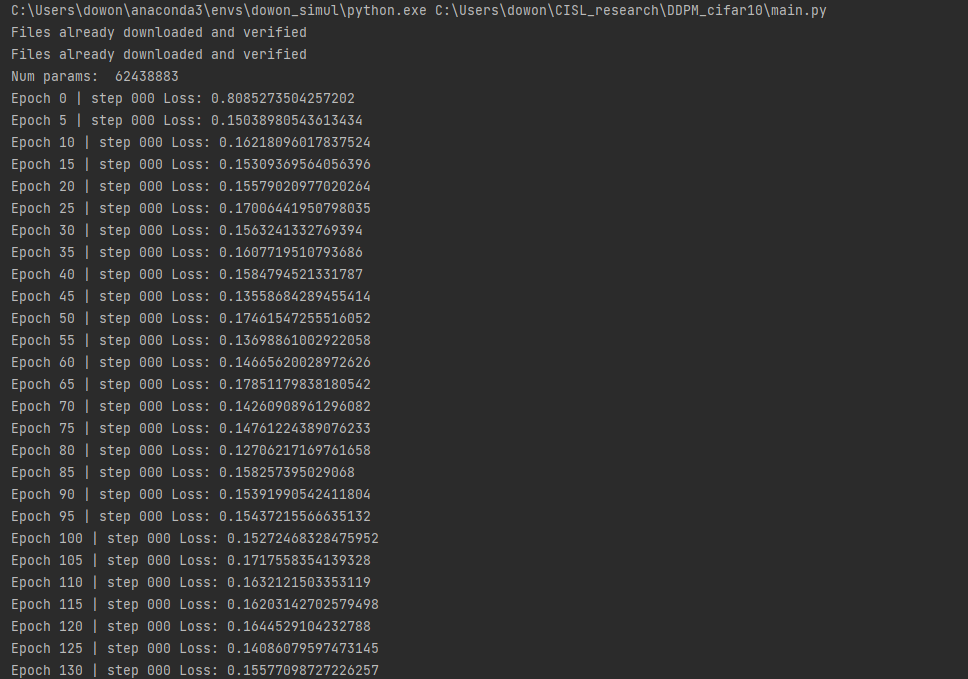


'Main' 카테고리의 다른 글
| High Attention Selection (0) | 2024.03.15 |
|---|---|
| Low Attention Selection (0) | 2024.03.15 |
| Patch selection with zero padding (0) | 2024.03.13 |
| cifar10 patch correlation map (0) | 2024.03.11 |
| DeepJSCC (0) | 2024.03.11 |
'Main' Related Articles
more



Comments