
UOMOP
[Plagiarism Scoring using DTW with Librosa's Chroma] 본문
Project/Music Plagiarism Project
[Plagiarism Scoring using DTW with Librosa's Chroma]
Happy PinGu 2022. 11. 4. 20:59def extractor(A, area, sr) :
# area = 01:31.5 ~ 02:18.3
area = str(area)
start = int(area[0]) * 600 + int(area[1]) * 60 + int(area[3]) * 10 + int(area[4]) * 1 + int(area[6]) /10
end = int(area[10]) * 600 + int(area[11]) * 60 + int(area[13]) * 10 + int(area[14]) * 1 + int(area[16]) /10
A_cut = A[int(start * sr) : int(end * sr)]
return A_cut
def chroma_score(song1, song1_plag_area, song2, song2_plag_area, sr, num_rand) :
# 나중에 모드를 여러개 정해보자.
# 만약 random이면 비교대상이 random이고, window면 주기적으로 window를 내는 방식이다.
song1_ext = np.array(extractor(song1, song1_plag_area, sr = sr))
song2_ext = np.array(extractor(song2, song2_plag_area, sr = sr))
song1_chroma = librosa.feature.chroma_stft(y = song1_ext, sr = sr)
song2_chroma = librosa.feature.chroma_stft(y = song2_ext, sr = sr)
#================================song1의 난수 생성================================
song1_start = int(song1_plag_area[0]) * 600 + int(song1_plag_area[1]) * 60 + int(song1_plag_area[3]) * 10 + int(song1_plag_area[4]) * 1 + int(song1_plag_area[6]) /10
song1_end = int(song1_plag_area[10]) * 600 + int(song1_plag_area[11]) * 60 + int(song1_plag_area[13]) * 10 + int(song1_plag_area[14]) * 1 + int(song1_plag_area[16]) /10
song1_len = int(len(song1) / sr)
song1_len_plag = int( song1_end - song1_start )
rand_range = song1_len - song1_len_plag
song1_rand_saver = random.sample( range(0, rand_range), num_rand )
print("song1_rand_saver Before : {}".format(song1_rand_saver))
for i in range(0, num_rand) :
while ( abs( song1_rand_saver[i] - int(song1_start) ) <= int(song1_len_plag / 2)) :
new_rand = random.sample( range(0, rand_range), 1 )
song1_rand_saver[i] = new_rand[0]
print("song1_rand_saver After : {}".format(song1_rand_saver))
#================================song2의 난수 생성================================
song2_start = int(song2_plag_area[0]) * 600 + int(song2_plag_area[1]) * 60 + int(song2_plag_area[3]) * 10 + int(song2_plag_area[4]) * 1 + int(song2_plag_area[6]) /10
song2_end = int(song2_plag_area[10]) * 600 + int(song2_plag_area[11]) * 60 + int(song2_plag_area[13]) * 10 + int(song2_plag_area[14]) * 1 + int(song2_plag_area[16]) /10
song2_len = int(len(song2) / sr)
song2_len_plag = int( song2_end - song2_start )
rand_range = song2_len - song2_len_plag
song2_rand_saver = random.sample( range(0, rand_range), num_rand )
print("song2_rand_saver Before : {}".format(song2_rand_saver))
for i in range(0, num_rand) :
while ( abs( song2_rand_saver[i] - int(song2_start) ) <= int(song2_len_plag / 2)) :
new_rand = random.sample( range(0, rand_range), 1 )
song2_rand_saver[i] = new_rand[0]
print("song2_rand_saver After : {}".format(song2_rand_saver))
#================================모든 난수 생성 완료================================
print("song1'의 랜덤한 시간(초) {}개 : {}".format(num_rand, song1_rand_saver))
print("song2'의 랜덤한 시간(초) {}개 : {}".format(num_rand, song2_rand_saver))
#================================song1 random data 저장 (2차원 배열로)================================
song1_rand_data = []
for i in range(0, num_rand) :
song1_rand_data.append([])
for j in range(0, len(song1_ext)) :
song1_rand_data[i].append(0)
for i in range(0, num_rand) :
song1_rand_data[i] = song1[song1_rand_saver[i] * sr : (song1_rand_saver[i] + song1_len_plag) * sr]
#================================song2 random data 저장 (2차원 배열로)================================
song2_rand_data = []
for i in range(0, num_rand) :
song2_rand_data.append([])
for j in range(0, len(song2_ext)) :
song2_rand_data[i].append(0)
for i in range(0, num_rand) :
song2_rand_data[i] = song2[song2_rand_saver[i] * sr : (song2_rand_saver[i] + song2_len_plag) * sr]
#================================모든 random data 생성 완료================================
print("song1 rand data's shape : {}".format(len(song1_rand_data)))
print("song2 rand data's shape : {}".format(len(song2_rand_data)))
#================================song1의 chroma Data 생성================================
song1_rand_chroma = []
for i in range(0, num_rand) :
song1_rand_chroma.append([])
for j in range(0, len(song1_chroma[0])) :
song1_rand_chroma[i].append(0)
for i in range(0, num_rand) :
song1_rand_chroma[i] = librosa.feature.chroma_stft(y = song1_rand_data[i], sr = sr)
#================================song2의 chroma Data 생성================================
song2_rand_chroma = []
for i in range(0, num_rand) :
song2_rand_chroma.append([])
for j in range(0, len(song2_chroma)) :
song2_rand_chroma[i].append(0)
for i in range(0, num_rand) :
song2_rand_chroma[i] = librosa.feature.chroma_stft(y = song2_rand_data[i], sr = sr)
#================================모든 chroma data 생성 완료================================
song1_rand_chroma = np.array(song1_rand_chroma)
song2_rand_chroma = np.array(song2_rand_chroma)
print("song1 chroma data's shape : {}".format(song1_rand_chroma.shape))
print("song2 chroma data's shape : {}".format(song2_rand_chroma.shape))
#================================chroma data 비교교================================
col_names = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B']
song1_vs_song2 = []
for i in range(0, 12) :
song1_vs_song2.append( FastDTW(song1_chroma[i], song2_chroma[i]) )
song1_vs_song2 = np.array(song1_vs_song2)
save_df = pd.DataFrame([song1_vs_song2], columns = col_names)
save_list = []
for i in range(0, num_rand) :
for j in range(0, 12) :
save_list.append( FastDTW(song1_chroma[j], song2_rand_chroma[i][j]) )
save_list = np.array(save_list)
save_list = pd.DataFrame([save_list], columns = col_names)
save_df = pd.concat([save_df, save_list])
save_list = []
for i in range(0, num_rand) :
for j in range(0, 12) :
save_list.append( FastDTW(song2_chroma[j], song1_rand_chroma[i][j]) )
save_list = np.array(save_list)
save_list = pd.DataFrame([save_list], columns = col_names)
save_df = pd.concat([save_df, save_list])
save_list = []
save_df.rename(columns = {'C' : 0, 'C#' : 1, 'D' : 2, 'D#' : 3,
'E' : 4, 'F' : 5, 'F#' : 6, 'G' : 7,
'G#' : 8, 'A' : 9, 'A#' : 10, 'B' : 11}, inplace = True)
score = 0
save_df = save_df.round(2)
save_df = save_df.reset_index(drop = True)
for i in range(0, 12) :
order = 0
save_df = save_df.sort_values(by = i)
index_saver = save_df.index
for j in range(0, len(index_saver)) :
if ( index_saver[j] != 0 ) :
order += 1
else :
order += 1
score += order
break
score = 100 - ((score - 11) /156 * 100)
print("=====================")
print("Chroma Score : {:.2f}점".format(score))
print("=====================")
save_df.rename(columns = {0 : 'C' , 1 : 'C#', 2 : 'D' , 3 : 'D#',
4 : 'E' , 5 : 'F' , 6 : 'F#', 7 : 'G' ,
8 : 'G#', 9 : 'A' , 10 : 'A#', 11 : 'B'}, inplace = True)
save_df = save_df.sort_index(ascending = True)
return save_df, scoresong1, sr = librosa.load("5-1.wav", sr = 22050)
song2, sr = librosa.load("5-2.wav", sr = 22050)
plag_1_1 = "00:00.0 ~ 00:07.5"
plag_1_2 = "00:00.0 ~ 00:07.5"
plag_2_1 = "00:30.7 ~ 00:39.0"
plag_2_2 = "00:42.7 ~ 00:51.0"
plag_3_1 = "00:39.5 ~ 00:52.5"
plag_3_2 = "02:22.3 ~ 02:35.3"
#plag_4_1 = "00:39.5 ~ 00:59.5"
#plag_4_2 = "02:22.3 ~ 02:42.3"
# 랩 노래는 나중에 다른 과정을 거쳐야할 것으로 보인다.
plag_5_1 = "01:09.2 ~ 01:15.5"
plag_5_2 = "01:03.5 ~ 01:10.0"
plag_6_1 = "00:12.3 ~ 00:25.5"
plag_6_2 = "00:41.9 ~ 00:54.3"
plag_7_1 = "00:39.5 ~ 00:59.5"
plag_7_2 = "02:22.3 ~ 02:42.3"
song1_plag_area = plag_5_1
song2_plag_area = plag_5_2
df, score = chroma_score(song1, song1_plag_area, song2, song2_plag_area, sr, num_rand = 7)
df.head(30)
표절 논란이 있는 노래를 Chroma Function에 넣었더니, 약 70점이 나옴.
연관이 없는 노래를 넣어보고 함수를 재확인.
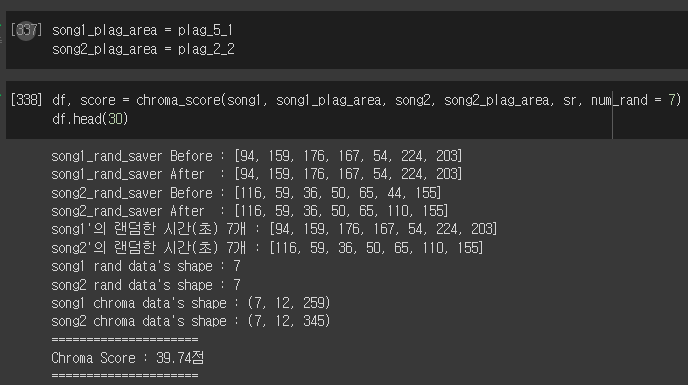
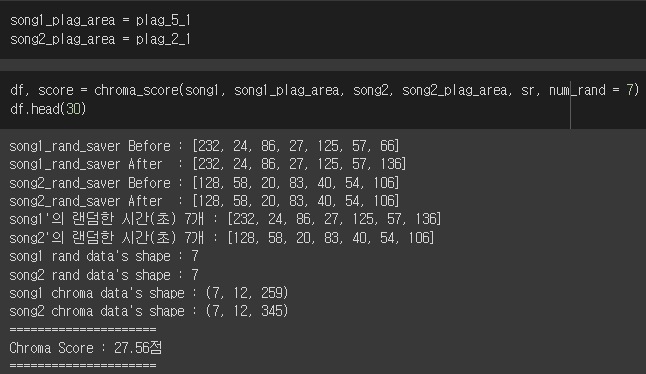
점수가 낮게 측정된다.
num_rand 파라미터를 7로 할 때가 이상적.

'Project > Music Plagiarism Project' 카테고리의 다른 글
| [Plagirism Scoring using Librosa's DTW (only time signal)] (1) | 2022.11.06 |
|---|---|
| [Librosa Tempo Problem] (0) | 2022.11.05 |
| [Music Genre Classification using LGBMClassifier (##Final##)] (0) | 2022.11.03 |
| Define Function : Music Genre Classification (0) | 2022.10.26 |
| Music Genre Classification using XGBoost (0) | 2022.10.26 |
'Project/Music Plagiarism Project' Related Articles
more




Comments