
UOMOP
[Music Genre Classification using LGBMClassifier (##Final##)] 본문
Project/Music Plagiarism Project
[Music Genre Classification using LGBMClassifier (##Final##)]
Happy PinGu 2022. 11. 3. 15:04import numpy as np
import pandas as pd
import librosa
import joblib
import matplotlib.pyplot as plt
import IPython.display as ipd
from xgboost import plot_importance
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from lightgbm import LGBMClassifierdef check_genre(song, sr, model) :
col_names_drop = ['chroma_stft_mean', 'chroma_stft_var',
'rms_mean', 'rms_var',
'spectral_centroid_mean', 'spectral_centroid_var',
'spectral_bandwidth_mean', 'spectral_bandwidth_var',
'rolloff_mean', 'rolloff_var',
'zero_crossing_rate_mean','zero_crossing_rate_var',
'harmony_mean', 'harmony_var',
'perceptr_mean', 'perceptr_var',
'tempo',
'mfcc1_mean', 'mfcc1_var', 'mfcc2_mean', 'mfcc2_var', 'mfcc3_mean', 'mfcc3_var', 'mfcc4_mean',
'mfcc4_var', 'mfcc5_mean', 'mfcc5_var', 'mfcc6_mean', 'mfcc6_var', 'mfcc7_mean', 'mfcc7_var', 'mfcc8_mean',
'mfcc8_var', 'mfcc9_mean', 'mfcc9_var', 'mfcc10_mean', 'mfcc10_var', 'mfcc11_mean', 'mfcc12_mean','mfcc12_var',
'mfcc13_mean', 'mfcc14_mean', 'mfcc15_mean','mfcc15_var', 'mfcc16_mean', 'mfcc16_var',
'mfcc17_mean', 'mfcc18_mean', 'mfcc18_var','mfcc19_mean', 'mfcc19_var', 'mfcc20_mean', 'mfcc20_var']
col_names = ['chroma_stft_mean', 'chroma_stft_var', 'rms_mean', 'rms_var',
'spectral_centroid_mean', 'spectral_centroid_var', 'spectral_bandwidth_mean',
'spectral_bandwidth_var', 'rolloff_mean', 'rolloff_var', 'zero_crossing_rate_mean',
'zero_crossing_rate_var', 'harmony_mean', 'harmony_var', 'perceptr_mean', 'perceptr_var',
'tempo', 'mfcc1_mean', 'mfcc1_var', 'mfcc2_mean', 'mfcc2_var', 'mfcc3_mean', 'mfcc3_var',
'mfcc4_mean','mfcc4_var', 'mfcc5_mean', 'mfcc5_var', 'mfcc6_mean', 'mfcc6_var', 'mfcc7_mean', 'mfcc7_var', 'mfcc8_mean',
'mfcc8_var', 'mfcc9_mean', 'mfcc9_var', 'mfcc10_mean', 'mfcc10_var', 'mfcc11_mean', 'mfcc11_var', 'mfcc12_mean',
'mfcc12_var', 'mfcc13_mean', 'mfcc13_var', 'mfcc14_mean', 'mfcc14_var', 'mfcc15_mean', 'mfcc15_var', 'mfcc16_mean',
'mfcc16_var', 'mfcc17_mean', 'mfcc17_var', 'mfcc18_mean', 'mfcc18_var', 'mfcc19_mean', 'mfcc19_var', 'mfcc20_mean', 'mfcc20_var']
data_3sec = pd.read_csv("features_3_sec.csv");
data_30sec = pd.read_csv("features_30_sec.csv");
data = pd.concat([data_3sec, data_30sec])
X = data.drop("label", axis = 1)
X_droped = X.drop(["filename", "length", "mfcc13_var", "mfcc17_var", "mfcc14_var", "mfcc11_var"], axis = 1, inplace = False)
chroma_shift = librosa.feature.chroma_stft(song, n_fft=2048, hop_length=512) # 음악의 크로마 특징
rmse = librosa.feature.rms(song, frame_length=512, hop_length=512) # RMS값
spectral_centroids = librosa.feature.spectral_centroid(song, sr=sr) # 스펙트럼 무게 중심
spec_bw = librosa.feature.spectral_bandwidth(song, sr=sr) # 스펙트럼 대역폭
spectral_rolloff = librosa.feature.spectral_rolloff(song, sr=sr)[0] # rolloff
zcr = librosa.feature.zero_crossing_rate(song, hop_length=512) # zero to crossing
y_harm, y_perc = librosa.effects.hpss(song) # 하모닉, 충격파
tempo, _ = librosa.beat.beat_track(song, sr=sr) # 템포
mfcc = librosa.feature.mfcc(song, sr=sr,n_mfcc=20) # mfcc 20까지 추출
features_extracted = np.hstack([
np.mean(chroma_shift),
np.var(chroma_shift),
np.mean(rmse),
np.var(rmse),
np.mean(spectral_centroids),
np.var(spectral_centroids),
np.mean(spec_bw),
np.var(spec_bw),
np.mean(spectral_rolloff),
np.var(spectral_rolloff),
np.mean(zcr),
np.var(zcr),
np.mean(y_harm),
np.var(y_harm),
np.mean(y_perc),
np.var(y_perc),
tempo,
np.mean(mfcc.T, axis=0),
np.var(mfcc.T, axis=0)
])
features = features_extracted.reshape(1, 57)
input_df = pd.DataFrame(features, columns = col_names)
input_df = input_df.drop(["mfcc13_var", "mfcc17_var", "mfcc14_var", "mfcc11_var"], axis = 1)
df_concated = pd.concat([X_droped, input_df], axis = 0)
ss = StandardScaler()
concat_scaled = ss.fit_transform(np.array(df_concated.iloc[:, :], dtype = float))
concat_df = pd.DataFrame(concat_scaled, columns = col_names_drop)
input_df = concat_df.iloc[-1]
input_df = pd.Series.to_frame(input_df)
input_arr = input_df.to_numpy()
input_arr = input_arr.reshape(1, 53)
input_df = pd.DataFrame(input_arr, columns = col_names_drop)
prediction = model.predict(input_df)
print("\n=====================")
print("Predicted Label : {}".format(prediction))
if prediction == 0:
answer = "blues"
elif prediction == 1:
answer = "classical"
elif prediction == 2:
answer = "country"
elif prediction == 3:
answer = "disco"
elif prediction == 4:
answer = "hiphop"
elif prediction == 5:
answer = "jazz"
elif prediction == 6:
answer = "metal"
elif prediction == 7:
answer = "pop"
elif prediction == 8:
answer = "reggae"
else:
answer = "rock"
print("This is {}!!".format(answer))
print("=====================")data_3sec = pd.read_csv("features_3_sec.csv");
data_30sec = pd.read_csv("features_30_sec.csv");
data = pd.concat([data_3sec, data_30sec])
X = data.drop("label", axis = 1)
y = data.iloc[:, -1]
cvt = preprocessing.LabelEncoder()
y_encoded = cvt.fit_transform(y)
X_droped = X.drop(["filename", "length", "mfcc13_var", "mfcc17_var", "mfcc14_var", "mfcc11_var"], axis = 1, inplace = False)
ss = StandardScaler()
X_scaled = ss.fit_transform(np.array(X_droped.iloc[:, :], dtype = float))
X_df = pd.DataFrame(X_scaled, columns = ['chroma_stft_mean', 'chroma_stft_var',
'rms_mean', 'rms_var',
'spectral_centroid_mean', 'spectral_centroid_var',
'spectral_bandwidth_mean', 'spectral_bandwidth_var',
'rolloff_mean', 'rolloff_var',
'zero_crossing_rate_mean','zero_crossing_rate_var',
'harmony_mean', 'harmony_var',
'perceptr_mean', 'perceptr_var',
'tempo',
'mfcc1_mean', 'mfcc1_var', 'mfcc2_mean', 'mfcc2_var', 'mfcc3_mean', 'mfcc3_var',
'mfcc4_mean', 'mfcc4_var', 'mfcc5_mean', 'mfcc5_var', 'mfcc6_mean', 'mfcc6_var',
'mfcc7_mean', 'mfcc7_var', 'mfcc8_mean', 'mfcc8_var', 'mfcc9_mean', 'mfcc9_var',
'mfcc10_mean', 'mfcc10_var', 'mfcc11_mean', 'mfcc12_mean','mfcc12_var',
'mfcc13_mean', 'mfcc14_mean', 'mfcc15_mean','mfcc15_var', 'mfcc16_mean', 'mfcc16_var',
'mfcc17_mean', 'mfcc18_mean', 'mfcc18_var','mfcc19_mean', 'mfcc19_var', 'mfcc20_mean', 'mfcc20_var'])
y_df = pd.DataFrame(y_encoded, columns = ['target'])
X_train, X_test, y_train, y_test = train_test_split(X_df, y_df, test_size = 0.2, random_state = 156, shuffle = True)
evals = [(X_test, y_test)]
print("X_train.shape : {}".format(X_train.shape))
print("y_train.shape : {}".format(y_train.shape))
print("X_test.shape : {}".format(X_test.shape))
print("y_test.shape : {}".format(y_test.shape))
model = LGBMClassifier(learning_rate = 0.06, n_estimators = 781, max_depth = 11, min_child_weight = 1,
gamma = 0, subsample = 1, colsample_bytree = 1, min_data_in_leaf = 28, num_leaves = 19,
booster = 'gbtree', importance_type = 'gain', scoring = "accuracy", n_jobs = -1, random_state = 777)
model.fit(X_train, y_train, eval_set = evals,eval_metric = "logloss", verbose = 0)
pred = model.predict(X_test)
predictions = [round(value) for value in pred]
accuracy = accuracy_score(y_test, predictions)
print("===================")
print("Accuracy : {:.2f} %".format(accuracy * 100))
print("===================")
joblib.dump(model, 'my_model.pkl')
model_called = joblib.load('my_model.pkl')model_called.fit(X_train, y_train, eval_set = evals,eval_metric = "logloss", verbose = 0)
pred = model_called.predict(X_test)
predictions = [round(value) for value in pred]
accuracy = accuracy_score(y_test, predictions)
print("===================")
print("Accuracy : {:.2f} %".format(accuracy * 100))
print("===================")
champion_22050, sr = librosa.load('1-1.wav', sr = 22050)
champion_16000, sr = librosa.load('1-1.wav', sr = 16000)
champion_8000, sr = librosa.load('1-1.wav', sr = 8000)
champion_4000, sr = librosa.load('1-1.wav', sr = 4000)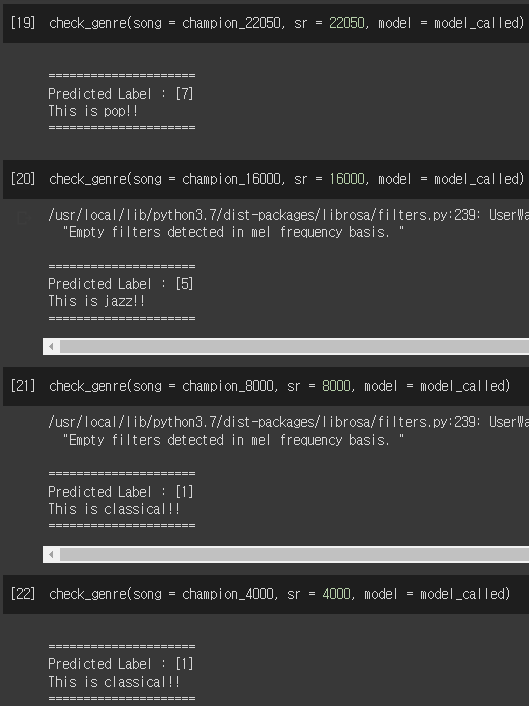
Sampling Rate은 임의로 낮추면 결과가 달라지는 것을 확인.
Feature 추출할 때 SR을 22050으로 해서.

'Project > Music Plagiarism Project' 카테고리의 다른 글
| [Librosa Tempo Problem] (0) | 2022.11.05 |
|---|---|
| [Plagiarism Scoring using DTW with Librosa's Chroma] (2) | 2022.11.04 |
| Define Function : Music Genre Classification (0) | 2022.10.26 |
| Music Genre Classification using XGBoost (0) | 2022.10.26 |
| Pearson Coefficient, DTW(Dynamic Time Wrapping) (0) | 2022.10.25 |
'Project/Music Plagiarism Project' Related Articles
more




Comments