

UOMOP
FLOPs (Proposed encoder) 본문
pip install fvcore
pip install thop
import torch
import torch.nn as nn
from thop import profile
# 수정된 Encoder 클래스
class Encoder(nn.Module):
def __init__(self, latent_dim):
super(Encoder, self).__init__()
self.latent_dim = latent_dim
# stride=2를 초반 레이어에 적용하고, kernel_size를 3으로 줄임
self.in1 = nn.Conv2d(3, 32, kernel_size=5, stride=2, padding=3)
self.in2 = nn.Conv2d(3, 32, kernel_size=5, stride=2, padding=3)
self.in3 = nn.Conv2d(3, 32, kernel_size=5, stride=2, padding=2)
self.in4 = nn.Conv2d(3, 32, kernel_size=5, stride=2, padding=0)
self.out1 = nn.Conv2d(32, 32, kernel_size=3, stride=2, padding=3)
self.out2 = nn.Conv2d(32, 32, kernel_size=3, stride=2, padding=3)
self.out3 = nn.Conv2d(32, 32, kernel_size=3, stride=2, padding=3)
self.out4 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=3)
self.prelu = nn.PReLU()
self.pool = nn.AdaptiveAvgPool2d((8, 8))
self.flatten = nn.Flatten()
self.linear = nn.Linear(2048, self.latent_dim)
# 초반 레이어에 stride=2를 적용하여 연산량을 줄임
self.essen = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1)
def forward(self, x):
height = x.shape[-1]
if height == 32:
encoder_level = 1
x = self.prelu(self.in1(x))
x = self.prelu(self.out1(x))
x = self.prelu(self.out2(x))
x = self.prelu(self.out3(x))
x = self.prelu(self.out4(x))
x = self.prelu(self.essen(x))
if height == 26:
encoder_level = 2
x = self.prelu(self.in2(x))
x = self.prelu(self.out2(x))
x = self.prelu(self.out3(x))
x = self.prelu(self.out4(x))
x = self.prelu(self.essen(x))
if height == 20:
encoder_level = 3
x = self.prelu(self.in3(x))
x = self.prelu(self.out3(x))
x = self.prelu(self.out4(x))
x = self.prelu(self.essen(x))
if height == 16:
encoder_level = 4
x = self.prelu(self.in4(x))
x = self.prelu(self.out4(x))
x = self.prelu(self.essen(x))
print(x.shape)
x = self.pool(x)
print(x.shape)
x = self.flatten(x)
encoded = self.linear(x)
return encoded, encoder_level
# 입력 이미지 크기 정의
input_sizes = [(1, 3, 32, 32), (1, 3, 26, 26), (1, 3, 20, 20), (1, 3, 16, 16)]
# Encoder 모델 생성
latent_dim = 256 # 예시로 설정한 latent dimension
encoder = Encoder(latent_dim)
# 각 입력 이미지 크기에 대한 FLOPs 계산
for input_size in input_sizes:
print(f"Input size: {input_size}")
dummy_input = torch.randn(input_size)
# thop을 사용하여 FLOPs과 파라미터 수 계산
flops, params = profile(encoder, inputs=(dummy_input,))
print(f"FLOPs: {flops/1000000}M")
print(f"Params: {params}\n")
print("="*80 + "\n")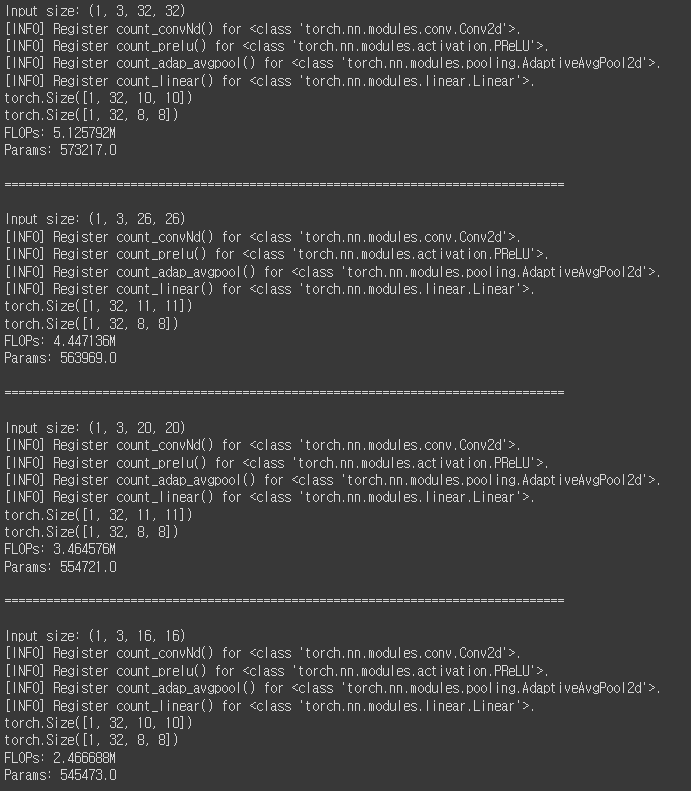
import torch
import torch.nn as nn
from thop import profile
# 정의한 Encoder 클래스
class Encoder(nn.Module):
def __init__(self, latent_dim):
super(Encoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=5, stride=2, padding=2), # Output: [batch, 16, 16, 16]
nn.PReLU(),
nn.Conv2d(16, 32, kernel_size=5, stride=2, padding=2), # Output: [batch, 32, 8, 8]
nn.PReLU(),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2), # Output: [batch, 32, 8, 8]
nn.PReLU(),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2), # Output: [batch, 32, 8, 8]
nn.PReLU(),
nn.Flatten(),
nn.Linear(2048, self.latent_dim),
)
def forward(self, x):
encoded = self.encoder(x)
#print(encoded.shape)
return encoded
# Encoder 모델 생성
latent_dim =256 # 예시로 설정한 latent dimension
encoder = Encoder(latent_dim)
# 32x32x3 이미지에 대한 FLOPs 계산
input_size = (1, 3, 32, 32) # 배치 크기 1, 채널 3, 이미지 크기 32x32
dummy_input = torch.randn(input_size)
# thop을 사용하여 FLOPs과 파라미터 수 계산
flops, params = profile(encoder, inputs=(dummy_input,))
print(f"FLOPs: {flops/1000000}M")
print(f"Params: {params}\n")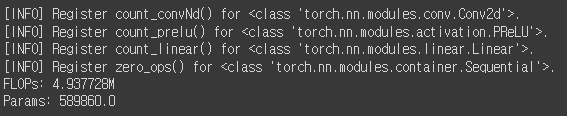
'DE > Code' 카테고리의 다른 글
| Transmission code 20240911 (0) | 2024.09.11 |
|---|---|
| Level decision model's MSE training (x+x_f, x, x_f) (0) | 2024.08.27 |
| Cifar10 Fourier (0) | 2024.08.27 |
| DE : Selection (33%, 60%, 75%) (0) | 2024.08.15 |
| Masked, Reshaped, index Gen (0) | 2024.08.10 |
'DE/Code' Related Articles
more



Comments