

UOMOP
No Encoder Symbol Check 본문
import math
import torch
import torchvision
from fractions import Fraction
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as f
import matplotlib.pyplot as plt
import torchvision.transforms as tr
from torchvision import datasets
from torch.utils.data import DataLoader, Dataset
import time
import os
from skimage.metrics import structural_similarity as ssim
from params import *
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
def vector_power(vector):
return vector.pow(2).sum()
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def calculate_ssim(batch1, batch2, win_size=3):
ssim_values = []
for img1, img2 in zip(batch1, batch2):
img1 = img1.detach().permute(1, 2, 0).cpu().numpy()
img2 = img2.detach().permute(1, 2, 0).cpu().numpy()
ssim_value = ssim(img1, img2, multichannel=True, data_range=img2.max() - img2.min(), win_size=win_size)
ssim_values.append(ssim_value)
return np.mean(ssim_values)
transf = tr.Compose([tr.ToTensor()])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transf)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transf)
trainloader = DataLoader(trainset, batch_size=params['BS'], shuffle=True)
testloader = DataLoader(testset, batch_size=params['BS'], shuffle=True)
class Decoder(nn.Module):
def __init__(self, latent_dim):
super(Decoder, self).__init__()
self.latent_dim = latent_dim
self.decoder = nn.Sequential(
nn.Linear(self.latent_dim, 4 * 4 * 128),
nn.ReLU(),
nn.Unflatten(1, (128, 4, 4)),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), # Output: [batch, 64, 8, 8]
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1), # Output: [batch, 32, 16, 16]
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(32, 3, kernel_size=4, stride=2, padding=1), # Output: [batch, 3, 32, 32]
nn.Sigmoid()
)
def forward(self, x):
return self.decoder(x)
class Autoencoder(nn.Module):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.decoder = Decoder(latent_dim)
def Power_norm(self, z, P=1 / np.sqrt(2)):
batch_size, z_dim = z.shape
z_power = torch.sqrt(torch.sum(z ** 2, 1))
z_M = z_power.repeat(z_dim, 1)
return np.sqrt(P * z_dim) * z / z_M.t()
def Power_norm_complex(self, z, P=1 / np.sqrt(2)):
batch_size, z_dim = z.shape
z_com = torch.complex(z[:, 0:z_dim:2], z[:, 1:z_dim:2])
z_com_conj = torch.complex(z[:, 0:z_dim:2], -z[:, 1:z_dim:2])
z_power = torch.sum(z_com * z_com_conj, 1).real
z_M = z_power.repeat(z_dim // 2, 1)
z_nlz = np.sqrt(P * z_dim) * z_com / torch.sqrt(z_M.t())
z_out = torch.zeros(batch_size, z_dim).to(device)
z_out[:, 0:z_dim:2] = z_nlz.real
z_out[:, 1:z_dim:2] = z_nlz.imag
return z_out
def AWGN_channel(self, x, snr, P=1):
batch_size, length = x.shape
gamma = 10 ** (snr / 10.0)
noise = np.sqrt(P / gamma) * torch.randn(batch_size, length).cuda()
y = x + noise
return y
def Fading_channel(self, x, snr, P=1):
gamma = 10 ** (snr / 10.0)
[batch_size, feature_length] = x.shape
K = feature_length // 2
h_I = torch.randn(batch_size, K).to(device)
h_R = torch.randn(batch_size, K).to(device)
h_com = torch.complex(h_I, h_R)
x_com = torch.complex(x[:, 0:feature_length:2], x[:, 1:feature_length:2])
y_com = h_com * x_com
n_I = np.sqrt(P / gamma) * torch.randn(batch_size, K).to(device)
n_R = np.sqrt(P / gamma) * torch.randn(batch_size, K).to(device)
noise = torch.complex(n_I, n_R)
y_add = y_com + noise
y = y_add / h_com
y_out = torch.zeros(batch_size, feature_length).to(device)
y_out[:, 0:feature_length:2] = y.real
y_out[:, 1:feature_length:2] = y.imag
return y_out
def forward(self, x, SNRdB, channel):
#print(1)
#print(x.shape)
batch_size = x.shape[0]
# 원본 이미지를 1차원 벡터로 변환
x_flattened = x.view(batch_size, -1)
#print(2)
#print(x_flattened.shape)
if channel == 'AWGN':
normalized_x = self.Power_norm(x_flattened)
channel_output = self.AWGN_channel(normalized_x, SNRdB)
elif channel == 'Rayleigh':
normalized_complex_x = self.Power_norm_complex(x_flattened)
channel_output = self.Fading_channel(normalized_complex_x, SNRdB)
decoded = self.decoder(channel_output)
return decoded
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# 데이터 로드
transf = tr.Compose([tr.ToTensor()])
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transf)
testloader = DataLoader(testset, batch_size=params['BS'], shuffle=False)
# 학습된 모델 로드
model_path = 'DeepJSCC(DIM=3072_SNR=40_PSNR=20.626_SSIM=0.81159).pt' # 여기에 실제 모델 경로를 입력하세요
model = torch.load(model_path)
model.eval()
# 테스트 데이터 로더
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transf)
testloader = DataLoader(testset, batch_size=1, shuffle=False)
# SNR 및 채널 설정
SNRdB = 40 # 실험하고자 하는 SNR 값 설정
channel = 'Rayleigh'
# 복소수 평면에 매핑할 y 값 누적 리스트
y_complex_list = []
with torch.no_grad():
for data in testloader:
inputs = data[0].to(device)
#encoded = model.encoder(inputs)
batch_size = inputs.shape[0]
# 원본 이미지를 1차원 벡터로 변환
x_flattened = inputs.view(batch_size, -1)
normalized_complex_x = model.Power_norm_complex(x_flattened)
y = model.Fading_channel(normalized_complex_x, SNRdB)
# 복소수 형태로 변환
batch_size, feature_length = y.shape
y_com = torch.complex(y[:, 0:feature_length:2], y[:, 1:feature_length:2])
# 복소수 평면에 매핑
y_complex_list.extend(y_com.cpu().numpy().flatten())
# y_complex_list를 2차원 복소수 평면에 시각화
y_complex_list = np.array(y_complex_list)
plt.figure(figsize=(10, 10))
plt.scatter(y_complex_list.real, y_complex_list.imag, s=1, alpha=0.5)
plt.xlim([-10, 10])
plt.ylim([-10, 10])
plt.title('Complex Plane Mapping of y in Fading Channel')
plt.xlabel('Real Part')
plt.ylabel('Imaginary Part')
plt.grid(True)
plt.show()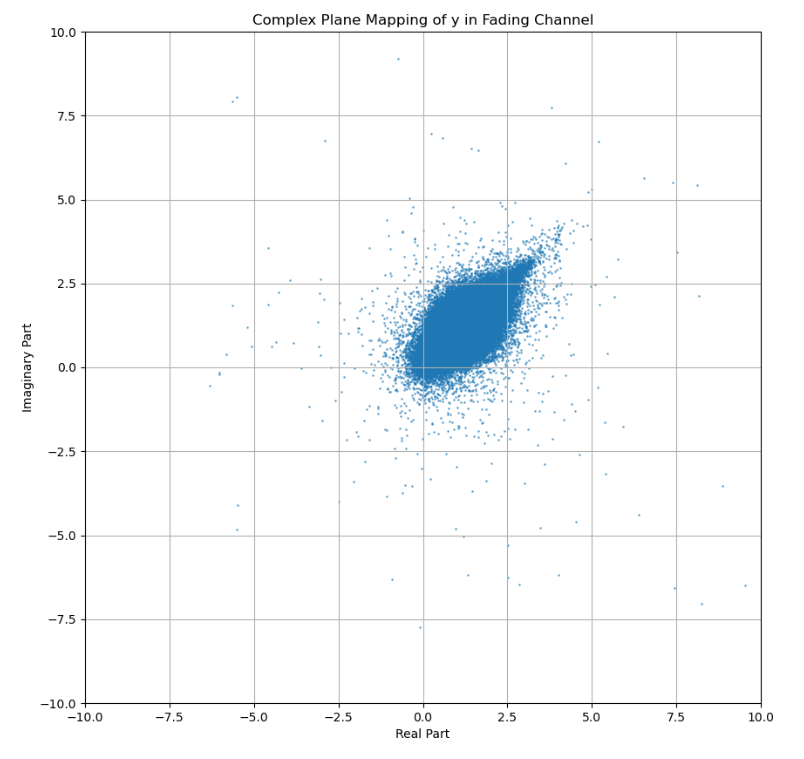
'Main' 카테고리의 다른 글
| CBS (0) | 2024.07.25 |
|---|---|
| Position Estimator (0) | 2024.07.10 |
| No Masking Symbol Check (0) | 2024.07.05 |
| Object/background focusing (0) | 2024.06.25 |
| Patch importance (0) | 2024.06.03 |
'Main' Related Articles
more




Comments