

UOMOP
판다스(Pandas) - 1 본문
read_csv() :
- read_csv()를 이용하여 csv파일을 편리하게 DataFrame으로 로딩한다.
- read_csv()의 sep 인자를 콤마(,)가 아닌 다른 분리자로 변경하여 다른 유형의 파일로 로드 가능
import pandas as pd
titanic_df = pd.read_csv("titanic_train.csv")
print("titanic 변수 type : {}".format(type(titanic_df)))titanic 변수 type : <class 'pandas.core.frame.DataFrame'>
head()
- DataFrame의 맨 앞 일부 데이터만 추출한다.
- default값은 5
- 가장 왼쪽에 있는 column이 index여서 column명이 없다.
titanic_df.head()
titanic_df.head(3)
DataFrame의 생성
dic1 = {"Name" : ["Dowon", "Junho", "Youngsu", "Bomi"],
"Year" : [2011, 2016, 2015, 2015],
"Gender" : ["Male", "Female", "Male", "Male"]}
# Dictionary를 DataFrame으로 변환
data_df = pd.DataFrame(dic1)
print(data_df)
print("-" * 30)
print("-" * 30)
# 새로운 column명을 추가
data_df = pd.DataFrame(dic1, columns=["Name", "Year", "Gender", "Age"])
print(data_df)
print("-" * 30)
print("-" * 30)
# 인덱스를 새로운 값으로 할당
data_df = pd.DataFrame(dic1, index = ["one", "two", "three", "four"])
print(data_df)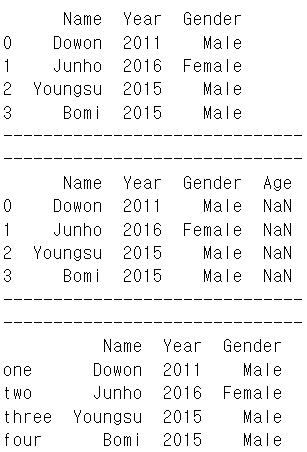
DataFrame의 컬럼명과 인덱스
- index ~> 인덱스의 범위를 반환
- index.value ~> 인덱스의 값들을 반환
print("columns : {}".format(titanic_df.columns))
print("index : {}".format(titanic_df.index))
print("index value : {}".format(titanic_df.index.values))
DataFrame에서 Series 추출 및 DataFrame 필터링 추출
- 일정 column의 Data를 추출할 때, 그냥 Key값 1개만 입력하면 Series로 반환이 된다.
- 만약, [Key]로 1개만 입력하게 되면 DataFrame으로 반환이 된다.
series = titanic_df["Name"]
print(series.head(3))
print("")
print("## type : {}".format(type(series)))
print("")
filtered_df = titanic_df[["Name", "Age"]]
print(filtered_df.head(3))
print("## type : {}".format(type(filtered_df)))
print("")
one_col_df = titanic_df[["Name"]]
print(one_col_df.head(3))
print("## type : {}".format(type(one_col_df)))
shape
- DataFrame의 행과 열 크기를 가지고 있는 속성
print("DataFrame 크기 : {}".format(titanic_df.shape))DataFrame 크기 : (891, 12)
- column 이 12이다. index는 column에 포함되지 않는다.
info()
- DataFrame 내의 컬럼명, 데이터 타입, Null건수, 데이터 건수 정보를 제공
titanic_df.info()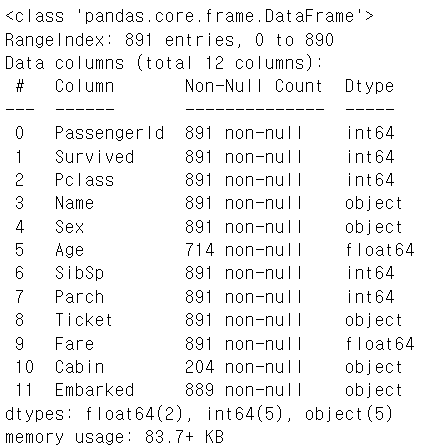
describe()
- 데이터 값들의 평균, 표준편차, 4분위 분포도를 제공.
- 숫자형 컬럼들에 대해서 해당 정보를 제공.
titanic_df.describe()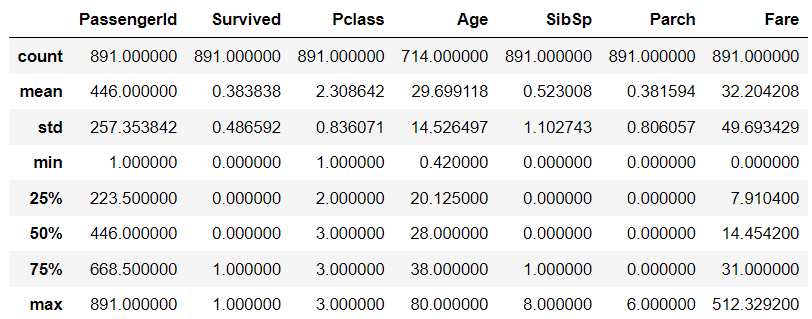
value_counts()
- 동일한 개별 데이터 값이 몇 건이 있는지 정보를 제공합니다. 즉, 개별 데이터 값의 분포도를 제공합니다. 주의할 점은 value_counts()는 Series 객체에서만 호출 될 수 있으므로 반드시 DataFrame을 단일 컬럼으로 입력하여 Seires로 변환한 뒤 호출합니다.
value_counts = titanic_df["Pclass"].value_counts()
print(value_counts)
print("")
print(type(value_counts))
sort_values()
- by = 정렬컬럼
- ascending = True of False로 오름차순/내림차순 정렬
titanic_df.sort_values(by = "Pclass", ascending = False)
# Pclass에 대해서 내림차순으로 정렬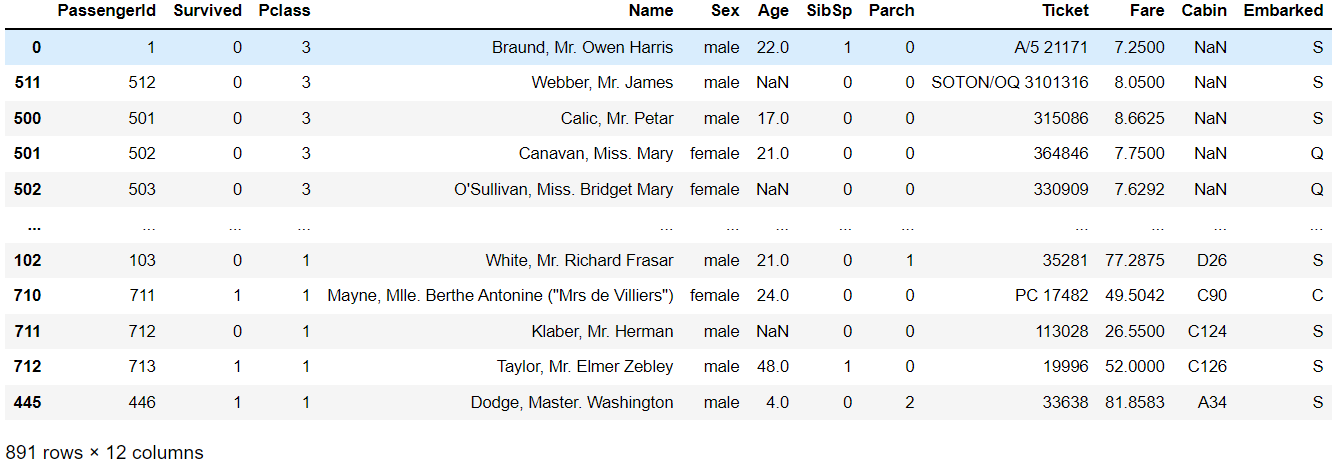
titanic_df[["Name", "Age"]].sort_values(by = "Age", ascending = True)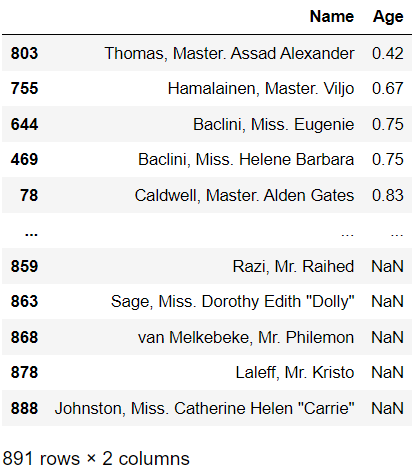
- 만약, Pclass에 대해서 먼저 정렬을 한 후에, 다시 나이에 대해서 정렬을 하고 싶다면 밑에 코드와 같이 작성
titanic_df[["Name", "Age", "Pclass"]].sort_values(by = ["Pclass", "Age"])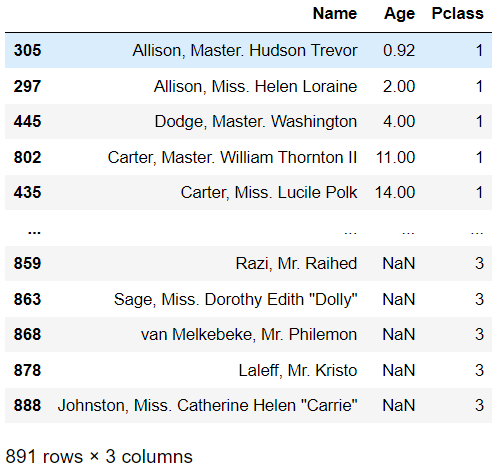
DataFrame의 column data set Access
titanic_df["Age_0"] = 0
titanic_df.head(3)
- "Age_0"이라는 새로운 컬럼이 생겼고 모든 값들은 0으로 초기화되었다.
titanic_df["Age_by_10"] = titanic_df["Age"] * 10
titanic_df["Family_No"] = titanic_df["SibSp"] + titanic_df["Parch"] + 1
titanic_df.head(3)
- 각종 연산을 통해서 컬럼의 값들을 초기화 해줄 수 있다.
titanic_df["Age_0"] = titanic_df["Age_0"] + 1
titanic_df.head(3)
DataFrame 데이터 삭제
titanic_drop_df = titanic_df.drop("Age_0", axis = 1, inplace = False)
titanic_drop_df.head(3)
titanic_df.head(3)
drop_result = titanic_df.drop(["Age_0", "Age_by_10", "Family_No"], axis = 1, inplace = True)
print("inplace = True 로 drop 후 반환된 값 : {}",format(drop_result))
titanic_df.head(3)
- axis = 0 일 경우 row방향으로 데이터 삭제
- axis = 1 일 경우 column방향으로 데이터 삭제
- inplace가 False일 때는 기존의 DataFrame에는 변화가 없다.
- inplace가 True일 때는 기존의 DataFrame이 변하고, 변환되는 값은 None이다.
print("#### before axis 0 drop ####")
titanic_df.head(3)
titanic_df.drop([0, 1, 2], axis = 0, inplace = True)
titanic_df.head(3)
Index 객체
# 원본 파일 재 로딩
titanic_df = pd.read_csv("titanic_train.csv")
# index 객체 추출
indexes = titanic_df.index
print(indexes)
# index 객체를 실제 값 array로 반환
print("index 객체 array의 값 : {}".format(indexes.values))

print(type(indexes.values))
print(indexes.values.shape)
print(indexes[:5].values)
print(indexes.values[:5])
print(indexes[6])<class 'numpy.ndarray'>
(891,)
[0 1 2 3 4]
[0 1 2 3 4]
6
- indexes[0] = 5 다음과 같이 인덱스의 값을 새롭게 초기화 할 수 없다.
titanic_df.head(3)
series_fair = titanic_df["Fare"]
series_fair.head(5)0 7.2500
1 71.2833
2 7.9250
3 53.1000
4 8.0500
Name: Fare, dtype: float64
print("Fair Series Max 값 : {}".format(series_fair.max()))
print("Fair Series Sum 값 : {}".format(sum(series_fair)))
print("")
print((series_fair+3).head(3))Fair Series Max 값 : 512.3292
Fair Series Sum 값 : 28693.949299999967
0 10.2500
1 74.2833
2 10.9250
Name: Fare, dtype: float64
- DataFrame 및 Series에 reset_index() 매서드를 수행하면 새롭게 인덱스를 연속 숫자 형으로 할당하며 기존 인덱스는 "index"라는 새로운 컬럼 명을 추가한다.
titanic_reset_df = titanic_df.reset_index(inplace = False)
titanic_reset_df.head(3)
titanic_reset_df.shape(891, 13)
print("### before reset_index ###")
value_counts = titanic_df["Pclass"].value_counts()
print(value_counts)
print("value_counts 객체 변수 타입 : {}".format(type(value_counts)))
print("")
new_value_counts = value_counts.reset_index(inplace = False)
print("### after reset_index ###")
print(new_value_counts)
print("new_value_counts 객체 변수 타입 : {}".format(type(new_value_counts)))
'Summary > Ai' 카테고리의 다른 글
| 판다스(Pandas) - 2 : 데이터 selection 및 filtering (0) | 2022.01.18 |
|---|---|
| 넘파이(Numpy) (0) | 2022.01.18 |
'Summary/Ai' Related Articles
more

Comments