
UOMOP
DDPM pytorch cifar10(train, validate) 본문
Research/Semantic Communication
DDPM pytorch cifar10(train, validate)
Happy PinGu 2023. 11. 21. 10:25import torch
from tqdm import tqdm
import torchvision
import matplotlib.pyplot as plt
from torch.optim import Adam
import torch.nn.functional as F
from torchvision import transforms
from torch.utils.data import DataLoader
import numpy as np
import torchvision.transforms as tr
from torch import nn
import math
import os
import time
torch.cuda.is_available()
args = {
'BATCH_SIZE': 128,
'LEARNING_RATE': 0.001,
'EPOCH': 100,
'IMG_SIZE' : 32
}
def show_images(datset, num_samples=12, cols=4):
""" Plots some samples from the dataset """
plt.figure(figsize=(7,7))
for i, img in enumerate(data):
if i == num_samples:
break
plt.subplot(int(num_samples/cols) + 1, cols, i + 1)
plt.imshow(img[0])
data = torchvision.datasets.CIFAR10(root = './data', download = True)
show_images(data)
def linear_beta_schedule(timesteps, start=0.0001, end=0.02):
return torch.linspace(start, end, timesteps)
def get_index_from_list(vals, t, x_shape):
"""
Returns a specific index t of a passed list of values vals
while considering the batch dimension.
"""
batch_size = t.shape[0]
out = vals.gather(-1, t.cpu())
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
def forward_diffusion_sample(x_0, t, device="cuda"):
"""
Takes an image and a timestep as input and
returns the noisy version of it
"""
noise = torch.randn_like(x_0)
sqrt_alphas_cumprod_t = get_index_from_list(sqrt_alphas_cumprod, t, x_0.shape)
sqrt_one_minus_alphas_cumprod_t = get_index_from_list(sqrt_one_minus_alphas_cumprod, t, x_0.shape)
# mean + variance
return sqrt_alphas_cumprod_t.to(device) * x_0.to(device) + sqrt_one_minus_alphas_cumprod_t.to(device) * noise.to(device), noise.to(device)
# Define beta schedule
T = 300
betas = linear_beta_schedule(timesteps=T)
# Pre-calculate different terms for closed form
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
'''
def load_transformed_dataset():
data_transforms = [
transforms.Resize((args['IMG_SIZE'], args['IMG_SIZE'])),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(), # Scales data into [0,1]
transforms.Lambda(lambda t: (t * 2) - 1) # Scale between [-1, 1]
]
data_transform = transforms.Compose(data_transforms)
train = torchvision.datasets.CIFAR10(root = './data', train = True, download = True, transform=data_transform)
test = torchvision.datasets.CIFAR10(root = './data', train = False, download = True, transform=data_transform)
return torch.utils.data.ConcatDataset([train, test])
'''
def show_tensor_image(image):
reverse_transforms = transforms.Compose([
transforms.Lambda(lambda t: (t + 1) / 2),
transforms.Lambda(lambda t: t.permute(1, 2, 0)), # CHW to HWC
transforms.Lambda(lambda t: t * 255.),
transforms.Lambda(lambda t: t.numpy().astype(np.uint8)),
transforms.ToPILImage(),
])
# Take first image of batch
if len(image.shape) == 4:
image = image[0, :, :, :]
plt.imshow(reverse_transforms(image))
transf = tr.Compose([
tr.ToTensor(),
tr.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root = './data', train = True, download = True, transform = transf)
testset = torchvision.datasets.CIFAR10(root = './data', train = False, download = True, transform = transf)
trainloader = DataLoader(trainset, batch_size = args['BATCH_SIZE'], shuffle = True, drop_last = True)
testloader = DataLoader(testset, batch_size = args['BATCH_SIZE'], shuffle = True, drop_last = True)
'''
# Simulate forward diffusion
image = next(iter(dataloader))[0]
plt.figure(figsize=(15,15))
plt.axis('off')
num_images = 10
stepsize = int(T/num_images)
j = 0
for idx in range(0, T, stepsize):
t = torch.Tensor([idx]).type(torch.int64)
plt.subplot(1, num_images+1, int(idx/stepsize) + 1)
plt.gca().axes.xaxis.set_visible(False)
plt.gca().axes.yaxis.set_visible(False)
plt.title("step : {}".format(j * stepsize))
j+= 1
img, noise = forward_diffusion_sample(image, t)
show_tensor_image(img)
'''
class Block(nn.Module):
def __init__(self, in_ch, out_ch, time_emb_dim, up=False):
super().__init__()
self.time_mlp = nn.Linear(time_emb_dim, out_ch)
if up:
self.conv1 = nn.Conv2d(2*in_ch, out_ch, 3, padding=1)
self.transform = nn.ConvTranspose2d(out_ch, out_ch, 4, 2, 1)
else:
self.conv1 = nn.Conv2d(in_ch, out_ch, 3, padding=1)
self.transform = nn.Conv2d(out_ch, out_ch, 4, 2, 1)
self.conv2 = nn.Conv2d(out_ch, out_ch, 3, padding=1)
self.bnorm1 = nn.BatchNorm2d(out_ch)
self.bnorm2 = nn.BatchNorm2d(out_ch)
self.relu = nn.ReLU()
def forward(self, x, t, ):
# First Conv
h = self.bnorm1(self.relu(self.conv1(x)))
# Time embedding
time_emb = self.relu(self.time_mlp(t))
# Extend last 2 dimensions
time_emb = time_emb[(..., ) + (None, ) * 2] # 이게 무슨 뜻일까
# Add time channel
h = h + time_emb
# Second Conv
h = self.bnorm2(self.relu(self.conv2(h)))
# Down or Upsample
return self.transform(h)
class SinusoidalPositionEmbeddings(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, time):
device = time.device
half_dim = self.dim // 2
embeddings = math.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
embeddings = time[:, None] * embeddings[None, :]
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
class SimpleUnet(nn.Module):
def __init__(self):
super().__init__()
image_channels = 3
down_channels = (64, 128, 256, 512, 1024) # 채널수(압축할 때)
up_channels = (1024, 512, 256, 128, 64) # 채널수(복원할 때)
out_dim = 3
time_emb_dim = 32 # time embedding vector의 dimension
# Time embedding
self.time_mlp = nn.Sequential(
SinusoidalPositionEmbeddings(time_emb_dim),
nn.Linear(time_emb_dim, time_emb_dim),
nn.ReLU()
)
# Initial projection : Original image를 받아서 채널 64개인 feature map을 생성
self.conv0 = nn.Conv2d(image_channels, down_channels[0], 3, padding=1)
# Downsample : Downsample할 block 을 미리 ModuleList에 저장.
self.downs = nn.ModuleList([ Block(down_channels[i], down_channels[i+1], time_emb_dim) for i in range(len(down_channels)-1) ])
# Upsample : Upsample할 block을 미리 ModuleList에 저장.
self.ups = nn.ModuleList([ Block(up_channels[i], up_channels[i+1], time_emb_dim, up=True) for i in range(len(up_channels)-1) ])
# 최종 output이 될 Conv2d : 64채널에서 3채널이 되는 과정.
self.output = nn.Conv2d(up_channels[-1], out_dim, 1)
def forward(self, x, timestep):
t = self.time_mlp(timestep) # Embedd time
x = self.conv0(x) # Initial conv
# Unet
residual_inputs = [] # skip connection을 하기 위해서 downsampling된 결과를 저장
for down in self.downs: # downs에는 현재 Modulelist가 담겨져있다.
x = down(x, t) # Modulelist 중 하나의 Block모델에 x(image feature map)과 t(Embedd time)이 input으로 들어감. feature map과 position map을 더해줌.
residual_inputs.append(x) # 그 결과를 list에 저장
for up in self.ups:
residual_x = residual_inputs.pop() # Down sampling한 결과의 마지막 output을 가져와서 residual_x를 초기화.
x = torch.cat((x, residual_x), dim=1) # residual_x와 실제 input을 concat
x = up(x, t) # Up sampling 진행
return self.output(x) # 64-channel feature map을 3-channel로 변환하면서 return해줌.
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SimpleUnet()
model.to(device)
#print("Num params: ", sum(p.numel() for p in model.parameters()))
def get_loss(model, x_0, t):
x_noisy, noise = forward_diffusion_sample(x_0, t, device)
noise_pred = model(x_noisy, t) # Unet은 noisy image와 그때의 time-step을 알게 되면 original image에서 얼만큼의 noise가 꼈는지 예측한다.
return F.l1_loss(noise, noise_pred)
@torch.no_grad()
def sample_timestep(x, t):
# Noise를 예측하는 model을 호출하고, denoising된 image를 반환한다.
# Forward process의 마지막 단계가 아니라면, image에 noise를 더한다.
betas_t = get_index_from_list(betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = get_index_from_list(sqrt_one_minus_alphas_cumprod, t, x.shape)
sqrt_recip_alphas_t = get_index_from_list(sqrt_recip_alphas, t, x.shape)
# Time_step t에서의 noisy image에서 predicted noise를 뺀 결과
model_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)
posterior_variance_t = get_index_from_list(posterior_variance, t, x.shape)
if t == 0:
return model_mean
else:
noise = torch.randn_like(x)
return model_mean + torch.sqrt(posterior_variance_t) * noise
@torch.no_grad()
def sample_plot_image():
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# Noise 샘플링 단계
img_size = args['IMG_SIZE']
img = torch.randn((1, 3, img_size, img_size), device=device)
plt.figure(figsize=(15, 15))
num_images = 10
stepsize = int(T / num_images)
for i in range(0, T)[::-1]:
t = torch.full((1,), i, device=device, dtype=torch.long)
img = sample_timestep(img, t)
img = torch.clamp(img, -1.0, 1.0)
if i % stepsize == 0:
plt.subplot(1, num_images, int(i / stepsize) + 1)
plt.gca().get_xaxis().set_visible(False)
plt.gca().get_yaxis().set_visible(False)
show_tensor_image(img.detach().cpu())
plt.show()
optimizer = Adam(model.parameters(), lr=args['LEARNING_RATE'])
epochs = args['EPOCH']
for epoch in range(epochs):
pred_noise_loss = 0.
mse_loss = 0.
for step, batch in enumerate(trainloader):
time_tmp = time.time()
print("step : {}".format(step+1))
# ================================ Train(check noise loss) ================================
model.train()
optimizer.zero_grad()
t = torch.randint(0, T, (args['BATCH_SIZE'],), device=device).long()
loss = get_loss(model, batch[0].to(device), t)
loss.backward()
optimizer.step()
pred_noise_loss += loss.item()
print("pred_noise_loss : {}".format(pred_noise_loss))
# ================================ Train(check noise loss) ================================
model.eval()
x_0 = batch[0].to(device)
t = torch.randint(T - 1, T, (args['BATCH_SIZE'],), device=device).long()
x_noisy, noise = forward_diffusion_sample(x_0, t, device)
for i in range(0, T)[::-1]:
t = torch.full((1,), i, device=device, dtype=torch.long)
x_noisy = sample_timestep(x_noisy, t)
x_noisy = torch.clamp(x_noisy, -1.0, 1.0)
min_val = x_noisy.min()
max_val = x_noisy.max()
x_noisy_normalized = 2 * ((x_noisy - min_val) / (max_val - min_val)) - 1
x_pred = x_noisy_normalized
mse_loss += nn.MSELoss()(x_0, x_pred).item()
print("mse_loss : {}".format(mse_loss))
print(f'elapsed : {time.time() - time_tmp}.2f')
print()
aver_noise_loss = pred_noise_loss / step
aver_mse_loss = mse_loss / step
aver_psnr_loss = round(10 * math.log10(2.0 / aver_mse_loss), 4)
# ================================ Test ================================
print("Epoch : {} | Pred Noise Loss : {} | PSNR : {}".format(epoch+1, aver_mse_loss, aver_psnr_loss))
sample_plot_image()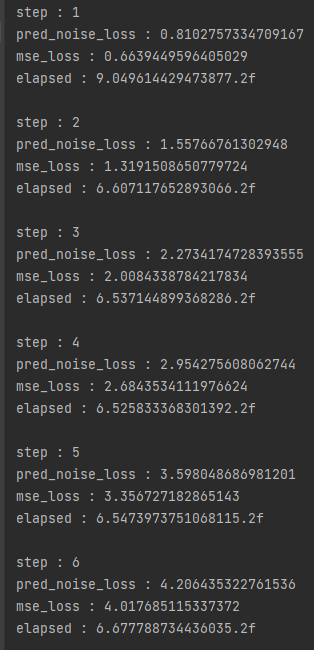

'Research > Semantic Communication' 카테고리의 다른 글
| DDPM_cifar10(BS : 128 | LR : 0.001 | L2 loss) (0) | 2023.11.21 |
|---|---|
| DDPM_cifar10(BS : 128 | LR : 0.001 | L1 loss) (2) | 2023.11.21 |
| iteration test_경향성 안보임 (1) | 2023.11.17 |
| iNet_2MLP_0.2DO (0) | 2023.11.13 |
| iNet_4MLP_0.2DO (1) | 2023.11.13 |
'Research/Semantic Communication' Related Articles
more




Comments