
UOMOP
[##midway check-up##] - Searching File with Button 본문
Project/Music Plagiarism Project
[##midway check-up##] - Searching File with Button
Happy PinGu 2022. 11. 8. 11:06# ========================= 라이브러리 호출 =========================
import sys
import time
import random
import joblib
import librosa
import numpy as np
import pandas as pd
import librosa.display
import matplotlib.pyplot as plt
from math import pi
from PyQt5 import uic
from scipy import stats
from fastdtw import fastdtw
from PyQt5.QtWidgets import *
from sklearn import preprocessing
from scipy.spatial.distance import euclidean
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from matplotlib.backends.backend_qt5agg import FigureCanvasQTAgg as FigureCanvas
gui_name = "test6_ui.ui"
form_class = uic.loadUiType(gui_name)[0]
class MyWindow(QMainWindow, form_class) :
def __init__(self):
super().__init__()
self.setUI()
self.setWindowTitle("Plagiarism Checker")
def setUI(self):
self.setupUi(self)
# 입력받을 파일주소
self.song1_address.setPlaceholderText("ex) C:/dowon/project/IU.wav")
self.song2_address.setPlaceholderText("ex) C:/dowon/project/IU.wav")
#클릭 시 메인함수 실행
self.pushButton.clicked.connect(self.start)
# 클릭시 파일 박스 오픈
self.search_1.clicked.connect(self.search_song1)
self.search_2.clicked.connect(self.search_song2)
def extractor(self, A, area, sr): # 영역을 시간으로 특정하면 해당 영역의 Data를 가져옴.
# area = 01:31.5 ~ 02:18.3
area = str(area)
# 추출할 영역의 시작점을 초 단위로 저장
start = int(area[0]) * 600 + int(area[1]) * 60 + int(area[3]) * 10 + int(area[4]) * 1 + int(area[6]) / 10
# 추출할 영역의 종료점을 초 단위로 저장
end = int(area[10]) * 600 + int(area[11]) * 60 + int(area[13]) * 10 + int(area[14]) * 1 + int(area[16]) / 10
# Sampling Rate을 곱해주고, 해당하는 값을 저장
A_cut = A[int(start * sr): int(end * sr)]
return A_cut
def FastDTW(self, A, B): # DTW 계산을 진행하고, 거리를 반환(값이 작을수록 유도가 높음)
distance, path = fastdtw(A, B, dist=euclidean)
return distance
def chroma_score(self, song1, song1_plag_area, song2, song2_plag_area, sr, rand_num): # chroma(12개의 음계)를 비교 분석
# 나중에 모드를 여러개 정해보자.
# 만약 random이면 비교대상이 random이고, window면 주기적으로 window를 내는 방식이다.
song1_ext = np.array(self.extractor(song1, song1_plag_area, sr=sr))
song2_ext = np.array(self.extractor(song2, song2_plag_area, sr=sr))
song1_chroma = librosa.feature.chroma_stft(y=song1_ext, sr=sr)
song2_chroma = librosa.feature.chroma_stft(y=song2_ext, sr=sr)
# ================================song1의 난수 생성================================
song1_start = int(song1_plag_area[0]) * 600 + int(song1_plag_area[1]) * 60 + int(song1_plag_area[3]) * 10 + int(
song1_plag_area[4]) * 1 + int(song1_plag_area[6]) / 10
song1_end = int(song1_plag_area[10]) * 600 + int(song1_plag_area[11]) * 60 + int(
song1_plag_area[13]) * 10 + int(song1_plag_area[14]) * 1 + int(song1_plag_area[16]) / 10
song1_len = int(len(song1) / sr)
song1_len_plag = int(song1_end - song1_start)
rand_range = song1_len - song1_len_plag
song1_rand_saver = random.sample(range(0, rand_range), rand_num)
cnt_1 = 0
for i in range(0, rand_num):
while (abs(song1_rand_saver[i] - int(song1_start)) <= int(song1_len_plag / 2)):
new_rand = random.sample(range(0, rand_range), 1)
song1_rand_saver[i] = new_rand[0]
cnt_1 += 1
# ================================song2의 난수 생성================================
song2_start = int(song2_plag_area[0]) * 600 + int(song2_plag_area[1]) * 60 + int(song2_plag_area[3]) * 10 + int(
song2_plag_area[4]) * 1 + int(song2_plag_area[6]) / 10
song2_end = int(song2_plag_area[10]) * 600 + int(song2_plag_area[11]) * 60 + int(
song2_plag_area[13]) * 10 + int(song2_plag_area[14]) * 1 + int(song2_plag_area[16]) / 10
song2_len = int(len(song2) / sr)
song2_len_plag = int(song2_end - song2_start)
rand_range = song2_len - song2_len_plag
song2_rand_saver = random.sample(range(0, rand_range), rand_num)
cnt_2 = 0
for i in range(0, rand_num):
while (abs(song2_rand_saver[i] - int(song2_start)) <= int(song2_len_plag / 2)):
new_rand = random.sample(range(0, rand_range), 1)
song2_rand_saver[i] = new_rand[0]
cnt_2 += 1
# ================================모든 난수 생성 완료================================
# ================================song1 random data 저장 (2차원 배열로)================================
song1_rand_data = []
for i in range(0, rand_num):
song1_rand_data.append([])
for j in range(0, len(song1_ext)):
song1_rand_data[i].append(0)
for i in range(0, rand_num):
song1_rand_data[i] = song1[song1_rand_saver[i] * sr: (song1_rand_saver[i] + song1_len_plag) * sr]
# ================================song2 random data 저장 (2차원 배열로)================================
song2_rand_data = []
for i in range(0, rand_num):
song2_rand_data.append([])
for j in range(0, len(song2_ext)):
song2_rand_data[i].append(0)
for i in range(0, rand_num):
song2_rand_data[i] = song2[song2_rand_saver[i] * sr: (song2_rand_saver[i] + song2_len_plag) * sr]
# ================================모든 random data 생성 완료================================
# ================================song1의 chroma Data 생성================================
song1_rand_chroma = []
for i in range(0, rand_num):
song1_rand_chroma.append([])
for j in range(0, len(song1_chroma[0])):
song1_rand_chroma[i].append(0)
for i in range(0, rand_num):
song1_rand_chroma[i] = librosa.feature.chroma_stft(y=song1_rand_data[i], sr=sr)
# ================================song2의 chroma Data 생성================================
song2_rand_chroma = []
for i in range(0, rand_num):
song2_rand_chroma.append([])
for j in range(0, len(song2_chroma[
0])): ####################################################################################
song2_rand_chroma[i].append(0)
for i in range(0, rand_num):
song2_rand_chroma[i] = librosa.feature.chroma_stft(y=song2_rand_data[i], sr=sr)
# ================================모든 chroma data 생성 완료================================
song1_rand_chroma = np.array(song1_rand_chroma)
song2_rand_chroma = np.array(song2_rand_chroma)
# ================================chroma data 비교교================================
col_names = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B']
song1_vs_song2 = []
for i in range(0, 12):
song1_vs_song2.append(self.FastDTW(song1_chroma[i], song2_chroma[i]))
song1_vs_song2 = np.array(song1_vs_song2)
save_df = pd.DataFrame([song1_vs_song2], columns=col_names)
save_list = []
for i in range(0, rand_num):
for j in range(0, 12):
save_list.append(self.FastDTW(song1_chroma[j], song2_rand_chroma[i][j]))
save_list = np.array(save_list)
save_list = pd.DataFrame([save_list], columns=col_names)
save_df = pd.concat([save_df, save_list])
save_list = []
for i in range(0, rand_num):
for j in range(0, 12):
save_list.append(self.FastDTW(song2_chroma[j], song1_rand_chroma[i][j]))
save_list = np.array(save_list)
save_list = pd.DataFrame([save_list], columns=col_names)
save_df = pd.concat([save_df, save_list])
save_list = []
save_df.rename(columns={'C': 0, 'C#': 1, 'D': 2, 'D#': 3,
'E': 4, 'F': 5, 'F#': 6, 'G': 7,
'G#': 8, 'A': 9, 'A#': 10, 'B': 11}, inplace=True)
score = 0
save_df = save_df.round(2)
save_df = save_df.reset_index(drop=True)
for i in range(0, 12):
order = 0
save_df = save_df.sort_values(by=i)
index_saver = save_df.index
for j in range(0, len(index_saver)):
if (index_saver[j] != 0):
order += 1
else:
order += 1
score += order
break
score = 100 - ((score - 12) / ((rand_num * 2 + 1) * 12) * 100)
save_df.rename(columns={0: 'C', 1: 'C#', 2: 'D', 3: 'D#',
4: 'E', 5: 'F', 6: 'F#', 7: 'G',
8: 'G#', 9: 'A', 10: 'A#', 11: 'B'}, inplace=True)
save_df = save_df.sort_index(ascending=True)
return round(score, 2)
def check_genre(self, song, sr, model):
col_names_drop = ['chroma_stft_mean', 'chroma_stft_var',
'rms_mean', 'rms_var',
'spectral_centroid_mean', 'spectral_centroid_var',
'spectral_bandwidth_mean', 'spectral_bandwidth_var',
'rolloff_mean', 'rolloff_var',
'zero_crossing_rate_mean', 'zero_crossing_rate_var',
'harmony_mean', 'harmony_var',
'perceptr_mean', 'perceptr_var',
'tempo',
'mfcc1_mean', 'mfcc1_var', 'mfcc2_mean', 'mfcc2_var', 'mfcc3_mean', 'mfcc3_var', 'mfcc4_mean',
'mfcc4_var', 'mfcc5_mean', 'mfcc5_var', 'mfcc6_mean', 'mfcc6_var', 'mfcc7_mean', 'mfcc7_var',
'mfcc8_mean',
'mfcc8_var', 'mfcc9_mean', 'mfcc9_var', 'mfcc10_mean', 'mfcc10_var', 'mfcc11_mean',
'mfcc12_mean', 'mfcc12_var',
'mfcc13_mean', 'mfcc14_mean', 'mfcc15_mean', 'mfcc15_var', 'mfcc16_mean', 'mfcc16_var',
'mfcc17_mean', 'mfcc18_mean', 'mfcc18_var', 'mfcc19_mean', 'mfcc19_var', 'mfcc20_mean',
'mfcc20_var']
col_names = ['chroma_stft_mean', 'chroma_stft_var', 'rms_mean', 'rms_var',
'spectral_centroid_mean', 'spectral_centroid_var', 'spectral_bandwidth_mean',
'spectral_bandwidth_var', 'rolloff_mean', 'rolloff_var', 'zero_crossing_rate_mean',
'zero_crossing_rate_var', 'harmony_mean', 'harmony_var', 'perceptr_mean', 'perceptr_var',
'tempo', 'mfcc1_mean', 'mfcc1_var', 'mfcc2_mean', 'mfcc2_var', 'mfcc3_mean', 'mfcc3_var',
'mfcc4_mean', 'mfcc4_var', 'mfcc5_mean', 'mfcc5_var', 'mfcc6_mean', 'mfcc6_var', 'mfcc7_mean',
'mfcc7_var', 'mfcc8_mean',
'mfcc8_var', 'mfcc9_mean', 'mfcc9_var', 'mfcc10_mean', 'mfcc10_var', 'mfcc11_mean', 'mfcc11_var',
'mfcc12_mean',
'mfcc12_var', 'mfcc13_mean', 'mfcc13_var', 'mfcc14_mean', 'mfcc14_var', 'mfcc15_mean',
'mfcc15_var', 'mfcc16_mean',
'mfcc16_var', 'mfcc17_mean', 'mfcc17_var', 'mfcc18_mean', 'mfcc18_var', 'mfcc19_mean',
'mfcc19_var', 'mfcc20_mean', 'mfcc20_var']
data_3sec = pd.read_csv(r"source/features_3_sec.csv");
data_30sec = pd.read_csv(r"source/features_30_sec.csv");
data = pd.concat([data_3sec, data_30sec])
X = data.drop("label", axis=1)
X_droped = X.drop(["filename", "length", "mfcc13_var", "mfcc17_var", "mfcc14_var", "mfcc11_var"], axis=1,
inplace=False)
chroma_shift = librosa.feature.chroma_stft(song, n_fft=2048, hop_length=512) # 음악의 크로마 특징
rmse = librosa.feature.rms(song, frame_length=512, hop_length=512) # RMS값
spectral_centroids = librosa.feature.spectral_centroid(song, sr=sr) # 스펙트럼 무게 중심
spec_bw = librosa.feature.spectral_bandwidth(song, sr=sr) # 스펙트럼 대역폭
spectral_rolloff = librosa.feature.spectral_rolloff(song, sr=sr)[0] # rolloff
zcr = librosa.feature.zero_crossing_rate(song, hop_length=512) # zero to crossing
y_harm, y_perc = librosa.effects.hpss(song) # 하모닉, 충격파
tempo, _ = librosa.beat.beat_track(song, sr=sr) # 템포
mfcc = librosa.feature.mfcc(song, sr=sr, n_mfcc=20) # mfcc 20까지 추출
features_extracted = np.hstack([
np.mean(chroma_shift),
np.var(chroma_shift),
np.mean(rmse),
np.var(rmse),
np.mean(spectral_centroids),
np.var(spectral_centroids),
np.mean(spec_bw),
np.var(spec_bw),
np.mean(spectral_rolloff),
np.var(spectral_rolloff),
np.mean(zcr),
np.var(zcr),
np.mean(y_harm),
np.var(y_harm),
np.mean(y_perc),
np.var(y_perc),
tempo,
np.mean(mfcc.T, axis=0),
np.var(mfcc.T, axis=0)
])
features = features_extracted.reshape(1, 57)
input_df = pd.DataFrame(features, columns=col_names)
input_df = input_df.drop(["mfcc13_var", "mfcc17_var", "mfcc14_var", "mfcc11_var"], axis=1)
df_concated = pd.concat([X_droped, input_df], axis=0)
ss = StandardScaler()
concat_scaled = ss.fit_transform(np.array(df_concated.iloc[:, :], dtype=float))
concat_df = pd.DataFrame(concat_scaled, columns=col_names_drop)
input_df = concat_df.iloc[-1]
input_df = pd.Series.to_frame(input_df)
input_arr = input_df.to_numpy()
input_arr = input_arr.reshape(1, 53)
input_df = pd.DataFrame(input_arr, columns=col_names_drop)
prediction = model.predict(input_df)
if prediction == 0:
answer = "blues"
elif prediction == 1:
answer = "classical"
elif prediction == 2:
answer = "country"
elif prediction == 3:
answer = "disco"
elif prediction == 4:
answer = "hiphop"
elif prediction == 5:
answer = "jazz"
elif prediction == 6:
answer = "metal"
elif prediction == 7:
answer = "pop"
elif prediction == 8:
answer = "reggae"
else:
answer = "rock"
return prediction[0]
def Data_PreProcessing(self, data1, data2):
data1 = pd.read_csv(data1);
data2 = pd.read_csv(data2);
data = pd.concat([data1, data2])
X = data.drop("label", axis=1)
y = data.iloc[:, -1]
cvt = preprocessing.LabelEncoder()
y_encoded = cvt.fit_transform(y)
X_droped = X.drop(["filename", "length", "mfcc13_var", "mfcc17_var", "mfcc14_var", "mfcc11_var"], axis=1,
inplace=False)
ss = StandardScaler()
X_scaled = ss.fit_transform(np.array(X_droped.iloc[:, :], dtype=float))
X_df = pd.DataFrame(X_scaled, columns=['chroma_stft_mean', 'chroma_stft_var',
'rms_mean', 'rms_var',
'spectral_centroid_mean', 'spectral_centroid_var',
'spectral_bandwidth_mean', 'spectral_bandwidth_var',
'rolloff_mean', 'rolloff_var',
'zero_crossing_rate_mean', 'zero_crossing_rate_var',
'harmony_mean', 'harmony_var',
'perceptr_mean', 'perceptr_var',
'tempo',
'mfcc1_mean', 'mfcc1_var', 'mfcc2_mean', 'mfcc2_var', 'mfcc3_mean',
'mfcc3_var',
'mfcc4_mean', 'mfcc4_var', 'mfcc5_mean', 'mfcc5_var', 'mfcc6_mean',
'mfcc6_var',
'mfcc7_mean', 'mfcc7_var', 'mfcc8_mean', 'mfcc8_var', 'mfcc9_mean',
'mfcc9_var',
'mfcc10_mean', 'mfcc10_var', 'mfcc11_mean', 'mfcc12_mean', 'mfcc12_var',
'mfcc13_mean', 'mfcc14_mean', 'mfcc15_mean', 'mfcc15_var', 'mfcc16_mean',
'mfcc16_var',
'mfcc17_mean', 'mfcc18_mean', 'mfcc18_var', 'mfcc19_mean', 'mfcc19_var',
'mfcc20_mean', 'mfcc20_var'])
y_df = pd.DataFrame(y_encoded, columns=['target'])
X_train, X_test, y_train, y_test = train_test_split(X_df, y_df, test_size=0.2, random_state=156, shuffle=True)
evals = [(X_test, y_test)]
return X_train, X_test, y_train, y_test, evals
def load_data(self, song1, song2, sr):
song1_data, sr = librosa.load(song1, sr=sr)
song2_data, sr = librosa.load(song2, sr=sr)
return song1_data, song2_data, sr
def tempo_score(self, song1, song2, sr):
song1_harm, song1_perc = librosa.effects.hpss(song1)
song1_zcr = librosa.feature.zero_crossing_rate(song1, hop_length=512)
song1_spectral_centroid = librosa.feature.spectral_centroid(song1, sr=sr)
song1_perceptr_var = np.var(song1_perc)
song1_zcr_var = np.var(song1_zcr)
song1_spectral_centroid_mean = np.mean(song1_spectral_centroid)
song1_perceptr_var_scaled = ((song1_perceptr_var - 4.67 * (10 ** -8)) / (0.058879 - 4.67 * (10 ** -8)))
song1_zcr_var_scaled = ((song1_zcr_var - 5.02 * (10 ** -6)) / (0.065185 - 5.02 * (10 ** -6)))
song1_spectral_centroid_scaled = ((song1_spectral_centroid_mean - 300) / (5432.534 - 300))
song1_score = np.mean(song1_perceptr_var_scaled + song1_zcr_var_scaled + song1_spectral_centroid_scaled)
song2_harm, song2_perc = librosa.effects.hpss(song2)
song2_zcr = librosa.feature.zero_crossing_rate(song2, hop_length=512)
song2_spectral_centroid = librosa.feature.spectral_centroid(song2, sr=sr)
song2_perceptr_var = np.var(song2_perc)
song2_zcr_var = np.var(song2_zcr)
song2_spectral_centroid_mean = np.mean(song2_spectral_centroid)
song2_perceptr_var_scaled = ((song2_perceptr_var - 4.67 * (10 ** -8)) / (0.058879 - 4.67 * (10 ** -8)))
song2_zcr_var_scaled = ((song2_zcr_var - 5.02 * (10 ** -6)) / (0.065185 - 5.02 * (10 ** -6)))
song2_spectral_centroid_scaled = ((song2_spectral_centroid_mean - 300) / (5432.534 - 300))
song2_score = np.mean(song2_perceptr_var_scaled + song2_zcr_var_scaled + song2_spectral_centroid_scaled)
song1_score = round(song1_score, 3)
song2_score = round(song2_score, 3)
tempo_score = round(100 - ((abs(song1_score - song2_score) / 1.2) * 100), 2)
return tempo_score
def dtw_score(self, song1, song1_plag_area, song2, song2_plag_area, sr, rand_num):
# 나중에 모드를 여러개 정해보자.
# 만약 random이면 비교대상이 random이고, window면 주기적으로 window를 내는 방식이다.
song1_ext = np.array(self.extractor(song1, song1_plag_area, sr=sr))
song2_ext = np.array(self.extractor(song2, song2_plag_area, sr=sr))
# ================================song1의 난수 생성================================
song1_start = int(song1_plag_area[0]) * 600 + int(song1_plag_area[1]) * 60 + int(song1_plag_area[3]) * 10 + int(
song1_plag_area[4]) * 1 + int(song1_plag_area[6]) / 10
song1_end = int(song1_plag_area[10]) * 600 + int(song1_plag_area[11]) * 60 + int(
song1_plag_area[13]) * 10 + int(song1_plag_area[14]) * 1 + int(song1_plag_area[16]) / 10
song1_len = int(len(song1) / sr)
song1_len_plag = int(song1_end - song1_start)
rand_range = song1_len - song1_len_plag
song1_rand_saver = random.sample(range(0, rand_range), rand_num)
cnt_1 = 0
for i in range(0, rand_num):
while (abs(song1_rand_saver[i] - int(song1_start)) <= int(song1_len_plag / 2)):
new_rand = random.sample(range(0, rand_range), 1)
song1_rand_saver[i] = new_rand[0]
cnt_1 += 1
# ================================song2의 난수 생성================================
song2_start = int(song2_plag_area[0]) * 600 + int(song2_plag_area[1]) * 60 + int(song2_plag_area[3]) * 10 + int(
song2_plag_area[4]) * 1 + int(song2_plag_area[6]) / 10
song2_end = int(song2_plag_area[10]) * 600 + int(song2_plag_area[11]) * 60 + int(
song2_plag_area[13]) * 10 + int(song2_plag_area[14]) * 1 + int(song2_plag_area[16]) / 10
song2_len = int(len(song2) / sr)
song2_len_plag = int(song2_end - song2_start)
rand_range = song2_len - song2_len_plag
song2_rand_saver = random.sample(range(0, rand_range), rand_num)
cnt_2 = 0
for i in range(0, rand_num):
while (abs(song2_rand_saver[i] - int(song2_start)) <= int(song2_len_plag / 2)):
new_rand = random.sample(range(0, rand_range), 1)
song2_rand_saver[i] = new_rand[0]
cnt_2 += 1
# ================================모든 난수 생성 완료================================
# ================================song1 random data 저장 (2차원 배열로)================================
song1_rand_data = []
for i in range(0, rand_num):
song1_rand_data.append([])
for j in range(0, len(song1_ext)):
song1_rand_data[i].append(0)
for i in range(0, rand_num):
song1_rand_data[i] = song1[song1_rand_saver[i] * sr: (song1_rand_saver[i] + song1_len_plag) * sr]
# ================================song2 random data 저장 (2차원 배열로)================================
song2_rand_data = []
for i in range(0, rand_num):
song2_rand_data.append([])
for j in range(0, len(song2_ext)):
song2_rand_data[i].append(0)
for i in range(0, rand_num):
song2_rand_data[i] = song2[song2_rand_saver[i] * sr: (song2_rand_saver[i] + song2_len_plag) * sr]
# ================================모든 random data 생성 완료================================
# ================================dtw scoring================================
saver = []
order = 0
song1song2 = self.FastDTW(song1_ext, song2_ext)
saver.append(song1song2)
for i in range(0, rand_num):
saver.append(self.FastDTW(song1_ext, song2_rand_data[i]))
saver.append(self.FastDTW(song2_ext, song1_rand_data[i]))
save_df = pd.DataFrame(saver, columns=['distance'])
save_df = save_df.sort_values(by='distance')
index_saver = save_df.index
for i in range(0, len(index_saver)):
if (index_saver[i] != 0):
order += 1
else:
order += 1
break
score = round(100 - ((order / (2 * rand_num + 1)) * 100), 2)
return score
def same_checker(self, song1, song2, sr):
pearson, _ = stats.pearsonr(np.array(song1[sr * 3:sr * 6]), np.array(song2[sr * 3:sr * 6]))
return abs(pearson)
def genre_score(self, song1, song2, sr, model):
conf_list = [[10, 2, 2, 2, 3, 1, 3, 0, 2, 4],
[0, 10, 0, 0, 0, 3, 0, 0, 0, 0],
[2, 0, 10, 1, 0, 6, 1, 1, 3, 2],
[1, 3, 1, 10, 4, 2, 1, 4, 1, 6],
[0, 0, 3, 2, 10, 0, 1, 5, 2, 1],
[4, 9, 7, 0, 0, 10, 1, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 10, 0, 0, 2],
[0, 1, 1, 2, 3, 0, 0, 10, 5, 2],
[0, 2, 3, 3, 4, 1, 0, 3, 10, 1],
[3, 1, 5, 1, 2, 2, 4, 1, 3, 10]]
conf_arr = np.array(conf_list)
song1_genre = self.check_genre(song1, sr=sr, model=model)
song2_genre = self.check_genre(song2, sr=sr, model=model)
genre_score = round(((conf_arr[song1_genre][song2_genre] + conf_arr[song2_genre][song1_genre]) / 20) * 100, 2)
return genre_score
def run_algo(self, song1, song1_plag_area, song2, song2_plag_area, sr, model, hard):
# hard : 7
same_score = self.same_checker(song1, song2, sr)
if same_score < 0.9:
genre = self.genre_score(song1, song2, sr, model)
chroma = self.chroma_score(song1, song1_plag_area, song2, song2_plag_area, sr, rand_num=hard)
tempo = self.tempo_score(song1, song2, sr=sr)
song1, song2, sr = self.load_data(song1_file, song2_file, sr=300)
dtw = self.dtw_score(song1, song1_plag_area, song2, song2_plag_area, sr=300, rand_num=hard - 2)
final_score = round((dtw * 45 + chroma * 30 + tempo * 15 + genre * 10) / 100, 2)
print(final_score)
else:
print("같은 노래를 입력하셨습니다.")
return final_score, genre, chroma, tempo, dtw
def start(self):
time.sleep(1)
global song1_file
global song2_file
song1_file = self.song1_address.text()
song2_file = self.song2_address.text()
start_boon_1 = self.song1_boon_start.value()
start_cho_1 = self.song1_cho_start.value()
end_boon_1 = self.song1_boon_end.value()
end_cho_1 = self.song1_cho_end.value()
start_boon_2 = self.song2_boon_start.value()
start_cho_2 = self.song2_cho_start.value()
end_boon_2 = self.song2_boon_end.value()
end_cho_2 = self.song2_cho_end.value()
if (int(start_cho_1) >= 10) :
if (int(end_cho_1) >= 10) :
song1_plag = str(0) + str(start_boon_1) + ":" + str(round(start_cho_1, 1)) + " ~ " + str(0) + str(end_boon_1)+ ":" + str(round(end_cho_1, 1))
else :
song1_plag = str(0) + str(start_boon_1) + ":" + str(round(start_cho_1, 1)) + " ~ " + str(0) + str(end_boon_1) + ":" + str(0) + str(round(end_cho_1, 1))
else :
if (int(end_cho_1) >= 10) :
song1_plag = str(0) + str(start_boon_1) + ":" + str(0) + str(round(start_cho_1, 1)) + " ~ " + str(0) + str(end_boon_1)+ ":" + str(round(end_cho_1, 1))
else :
song1_plag = str(0) + str(start_boon_1) + ":" + str(0) + str(round(start_cho_1, 1)) + " ~ " + str(0) + str(end_boon_1) + ":" + str(0) + str(round(end_cho_1, 1))
if (int(start_cho_2) >= 10) :
if (int(end_cho_2) >= 10) :
song2_plag = str(0) + str(start_boon_2) + ":" + str(round(start_cho_2, 1)) + " ~ " + str(0) + str(end_boon_2)+ ":" + str(round(end_cho_2, 1))
else :
song2_plag = str(0) + str(start_boon_2) + ":" + str(round(start_cho_2, 1)) + " ~ " + str(0) + str(end_boon_2) + ":" + str(0) + str(round(end_cho_2, 1))
else :
if (int(end_cho_1) >= 10) :
song2_plag = str(0) + str(start_boon_2) + ":" + str(0) + str(round(start_cho_2, 1)) + " ~ " + str(0) + str(end_boon_2)+ ":" + str(round(end_cho_2, 1))
else :
song2_plag = str(0) + str(start_boon_2) + ":" + str(0) + str(round(start_cho_2, 1)) + " ~ " + str(0) + str(end_boon_2) + ":" + str(0) + str(round(end_cho_2, 1))
print(song1_plag)
print(song2_plag)
### Train Data, Test Data, Evaluation Data
X_train, X_test, y_train, y_test, evals = self.Data_PreProcessing("source/features_3_sec.csv", "source/features_30_sec.csv")
### Call ML model (LGBMClassifier)
model = joblib.load(r'source/my_model.pkl')
song1_plag_area = song1_plag
song2_plag_area = song2_plag
### 음원 Data 2개, Sampling Rate
song1, song2, sr = self.load_data(song1_file, song2_file, sr=22050)
final_score, genre, chroma, tempo, dtw = self.run_algo(song1, song1_plag_area, song2, song2_plag_area, sr, model=model, hard=10)
global fin_score
fin_score = final_score
global genre_score
genre_score = genre
global chroma_score
chroma_score = chroma
global tempo_score
tempo_score = tempo
global dtw_score
dtw_score = dtw
score_list = [genre, chroma, tempo, dtw]
self.drawGraph()
def drawGraph(self):
self.fig = plt.Figure()
self.canvas = FigureCanvas(self.fig)
self.verticalLayout.addWidget(self.canvas)
df = pd.DataFrame(
data={'genre': [genre_score],
'chroma': [chroma_score],
'tempo': [tempo_score],
'dtw': [dtw_score]},
columns=['genre', 'chroma', 'tempo', 'dtw']
)
var = df.columns.to_list()[0:]
val_1st = df.loc[0, :].values.tolist()
val_1st += val_1st[:1]
num_var = len(var)
deg = [n /float(num_var) * 2 * pi for n in range(num_var)]
deg += deg[:1]
ax = self.fig.add_subplot(111, polar=True)
ax.set_xticks(deg[:-1])
ax.set_xticklabels(var, color="g", size=9)
ax.set_rlabel_position(45)
ax.set_yticks(range(0, 125, 25))
ax.set_ylim([0, 100])
ax.set_yticklabels([0, 25, 50, 75, 100], color="y", size=10)
ax.plot(deg, val_1st, linewidth=1, linestyle='solid')
ax.fill(deg, val_1st, 'g', alpha=0.2)
if (fin_score <= 72) :
spk = "Score : " + str(fin_score) + " Not Plagiarism!"
else :
spk = "Score : " + str(fin_score) + " Plagiarism!"
ax.set_title(spk)
self.canvas.draw()
def search_song1(self):
fname_1 = QFileDialog.getOpenFileName(self)
self.song1_address.setText(fname_1[0])
def search_song2(self):
fname_2 = QFileDialog.getOpenFileName(self)
self.song2_address.setText(fname_2[0])
if __name__ == "__main__" :
print("hello world");
app = QApplication(sys.argv)
myApp = MyWindow()
myApp.show()
app.exec_()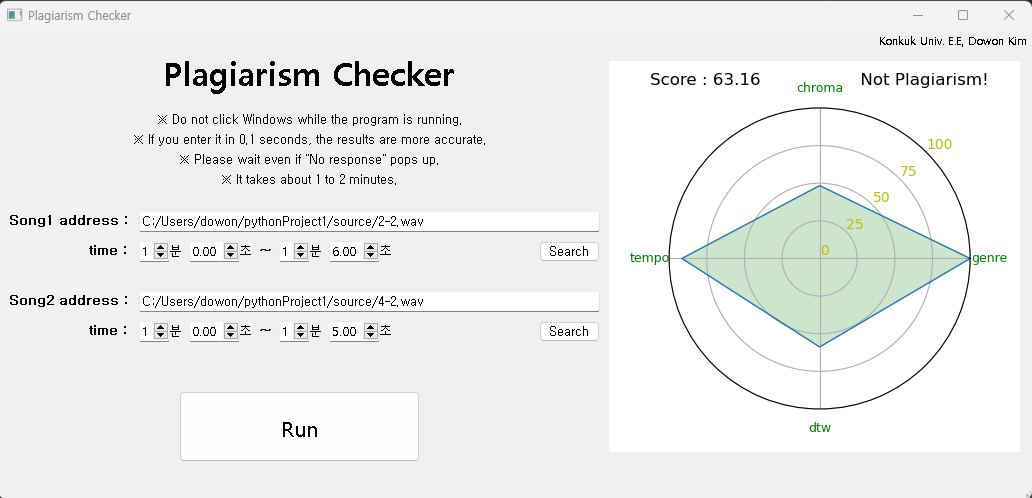

'Project > Music Plagiarism Project' 카테고리의 다른 글
| [tester(hard_level = 7, sr_level = 100)] (0) | 2022.11.10 |
|---|---|
| [tester(hard_level = 6, sr_level = 100)] (0) | 2022.11.10 |
| [##midway check-up##] - PyQt5 (0) | 2022.11.07 |
| [##midway check-up##] - 2 (0) | 2022.11.07 |
| [##midway check-up##] (0) | 2022.11.06 |
'Project/Music Plagiarism Project' Related Articles
more




Comments